Abstract
This article introduces how to craft a smart GPT-based customer support chatbot that can answer users’ questions and interact with them by applying different kinds of techniques from OpenAI.
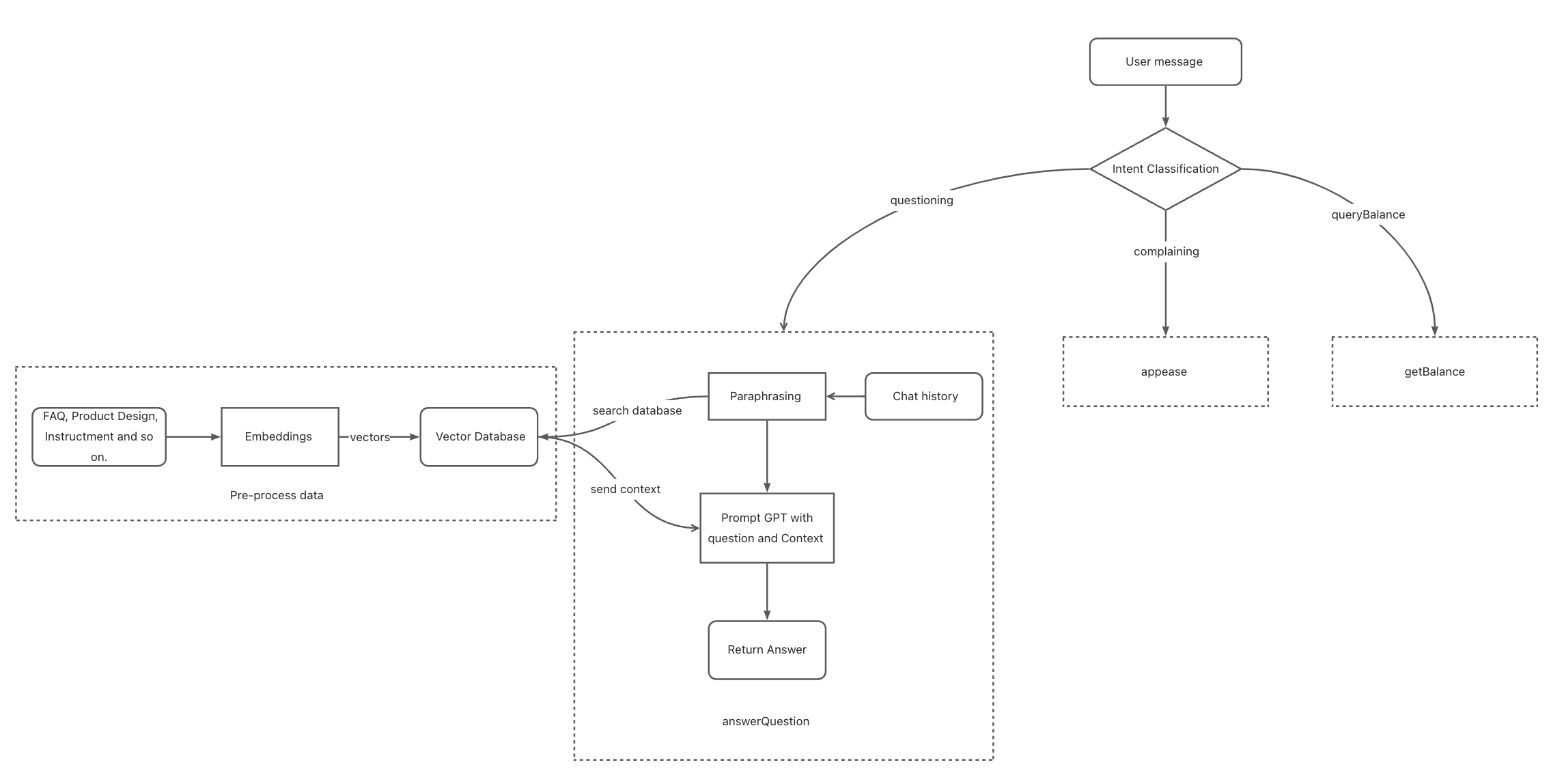
The techniques we use mainly include:
- Embeddings: This technique turns our knowledge base (documents like FAQs and product designs) into a set of vectors, so that we can easily search for related contexts for a question by comparing the vectors of text. Learn more about embeddings from the OpenAI API.
- “Few-shot” Prompting: By providing a few examples to GPT, we can let it easily learn how to solve a new task. This is called “few-shot” prompting. Learn more about in-context learning from Wikipedia.
- Vector Database (Vector Similarity Search Engine): This is where we store the vectors after processing embeddings. It provides a convenient and highly efficient search API for finding the top k closest vectors.
- Paraphrasing: In order to make our chatbot aware of context, we need to paraphrase users’ questions to provide contextual information.
- Intent Classification: To allow our chatbot to process different types of tasks, we need to classify the type of query first to decide which instruction we will use. Intent classification is a technique that classifies query intention based on GPT.
Stage 1: Answering Customers’ Questions Based on Documents
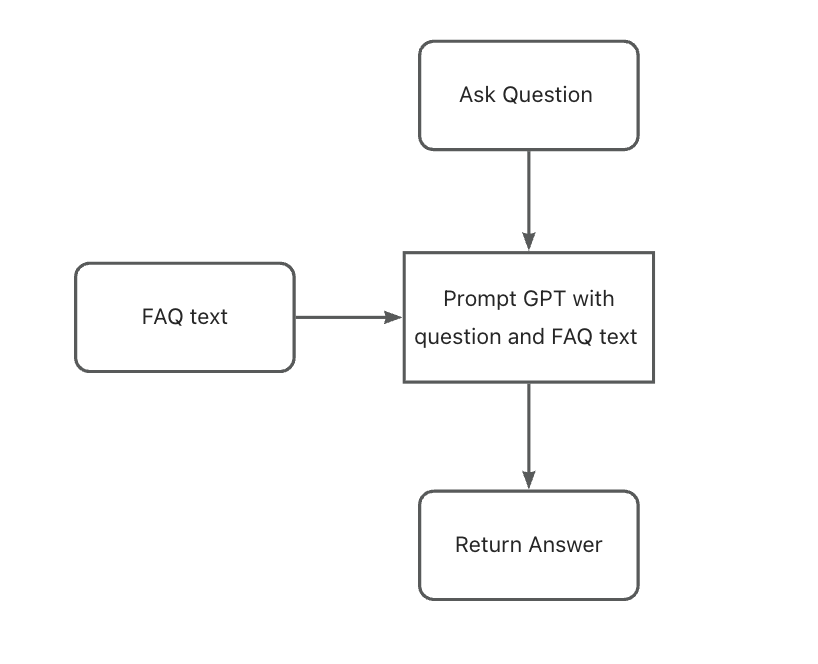
Answering questions using GPT-3.5 with a few FAQ texts
It is easy to let GPT answer questions based on short texts. We will create a function that calls the OpenAI GPT-3.5 model with reference text and the user’s question when they ask a question.
Scaling to Answer Questions with Embeddings and Vector Database
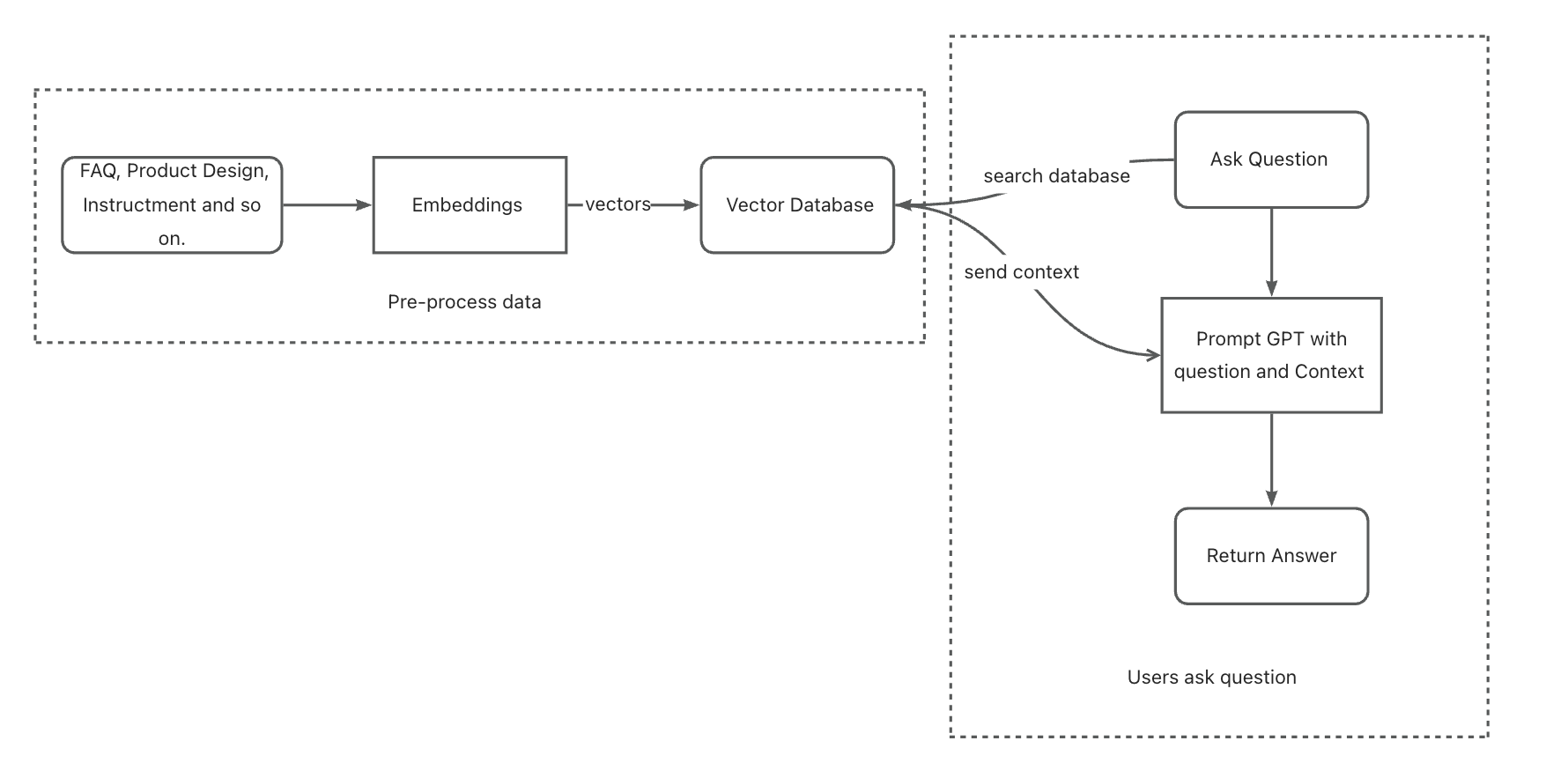
Our chatbot needs to remember more text without consuming too many tokens when asking questions. However, GPT has limitations when it comes to remembering a lot of text. To address this issue, we will introduce Embeddings and Vector Database to our system.
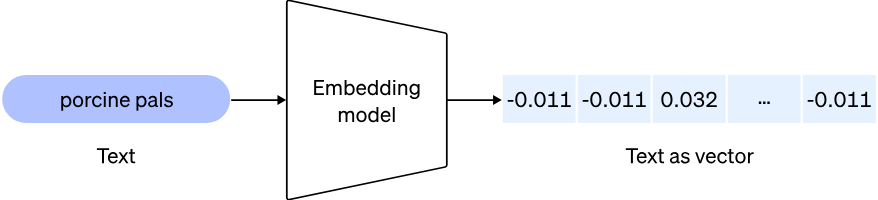
To start, we will use openai’s embeddings model "text-embedding-ada-002" to process a large document as data for our chatbot. This will turn the text into a set of vectors.
After that, we will store those vectors in a vector database called qdrant. This will allow us to later query the text snippets that are most related to the user’s questions.
When a user asks a question, our chatbot will first query context information in the vector database. It will then bring together that context with the question to prompt GPT.
Stage 2: Supporting Contextual Answering
Our chatbot can answer users’ different questions no matter how large the knowledge base is. However, there is still a critical issue: the chatbot cannot remember the chat history between the user and itself. For example, if a user asks, “What is A?” and our chatbot answers, “A is xxxx…,” and then the user asks another question, “Do I need to connect to the internet to use it?” Our chatbot is likely unable to answer that because it doesn’t know what “it” means.
To address this issue, we introduce a technique called paraphrasing, which allows us to restructure the question before asking our chatbot. During paraphrasing, we replace some words like “it” in user questions (paraphrasing does more than that; it also optimizes the question) according to the chat history. We use GPT to accomplish this task.
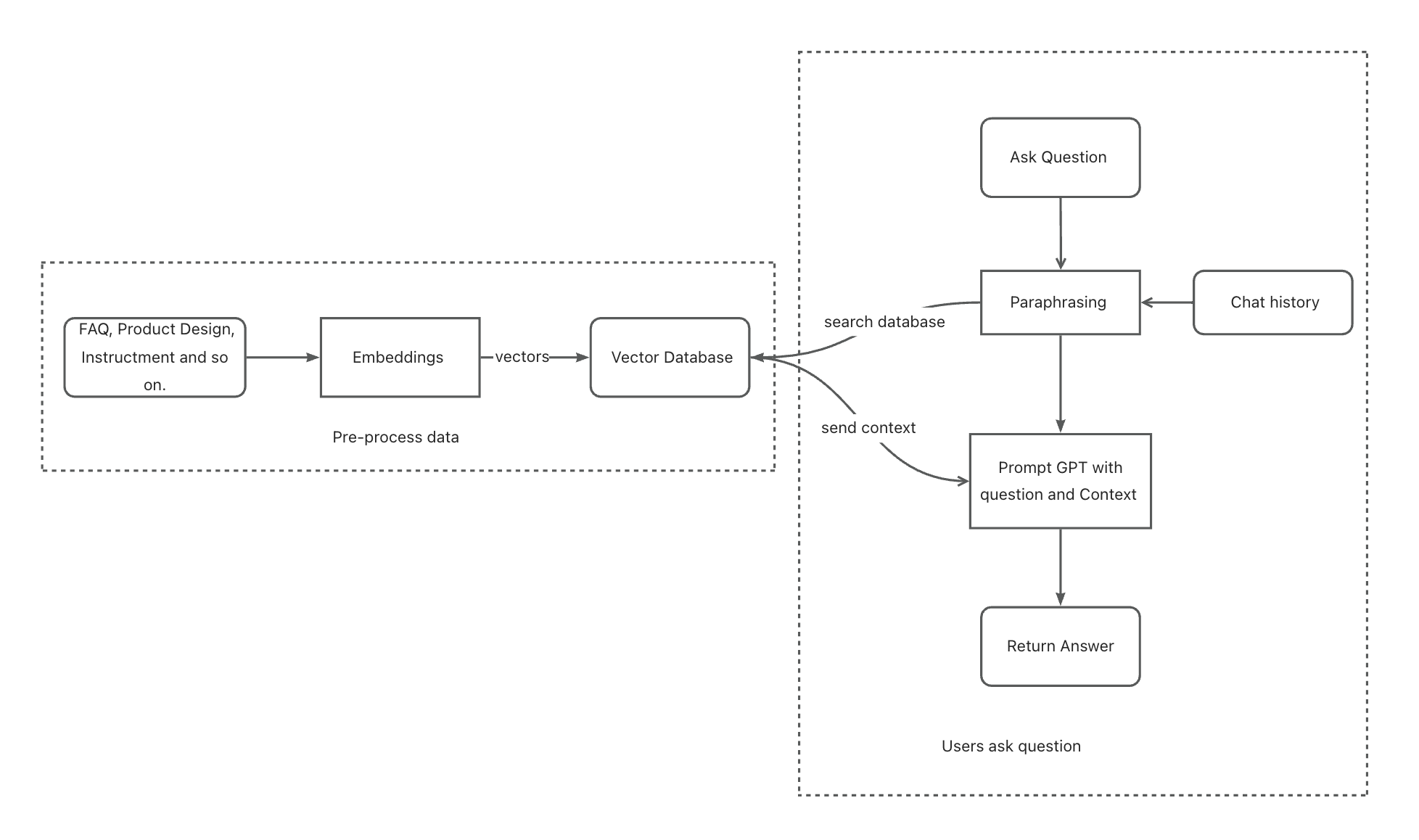
Prompting Engineering Improvement during Paraphrasing
We use “Few-shot” Prompting to help GPT better understand how to paraphrase questions based on context.
Before letting GPT paraphrase questions, we will provide a practice round. The prompt will be similar to the following example, which can be adjusted as needed:
1 | [ |
Stage 3: Supporting Appeasing Customers and Calling External APIs
We want our chatbot to be able to handle more types of tasks, not just answering questions. For example, we want it to appease customers who are complaining, or we want it to call an API to query a user’s balance when they ask about their money.
To provide this ability, we add another layer to analyze the user’s intention before handling the task. This step is called Intent Classification.
How can we know what the user really wants based on their message? GPT is good at this task. Refer to Intent Classification - OpenAI for more information.
Modularity: We can now treat our previous process as a module called the answerQuestion module. Assuming we have two more modules, namely the appease and getBalance modules, we can create three categories of user intention: questioning, complaining, and queryingBalance (just examples).
When a user sends a message, we prompt GPT as follows:
System: You will be provided with customer service queries. Classify each query into different categories. Provide your output in JSON format with the keys: category.
Categories: questioning, complaining, queryingBalance.
User: Your product is a piece of s@it!
After we get the JSON with categories, we can start calling the corresponding module to handle the user’s message. This way we don’t mix different types of tasks together, which makes our system more scalable.
Summary
In this article, we learn how to craft a customer support chatbot using the latest GPT techniques from simple to complex. We will introduce you to techniques such as embeddings, “few-shot” prompting, vector database, paraphrasing, and intent classification. The article also details the process of scaling the chatbot and supporting contextual answering, appeasing customers, and calling external APIs. Our approach is guided by software engineering principles such as modularity, making the chatbot more scalable and easier to manage.