背景
当我们说某人的代码质量不好时,大多数情况下,我们真正的意思是代码难以理解。许多开发者宁愿从零开始一个新项目,也不愿在遗留项目上添加功能,因为理解代码的心智成本远高于创造新事物的成本。随着项目功能的增加,代码不可避免地变得更难理解。因此,有一种方法来衡量和控制代码的复杂性和可理解性非常重要。
在这篇文章中,我将介绍两种主流的代码复杂度度量方法——圈复杂度(Cyclomatic Complexity) 和 认知复杂度(Cognitive Complexity)。在解释为什么圈复杂度并不总是足够的同时,我也会向你介绍认知复杂度。并通过它的规则,解释哪些编程行为会让代码更难理解。
圈复杂度
圈复杂度最初被提出是作为衡量模块控制流的**”可测试性和可维护性”**的指标。
圈复杂度通过以下指标来衡量代码复杂度:
- 决策点数量:代码中决策点的数量,例如循环、条件语句和 case 语句。
- 独立路径数量:代码中独立路径的数量。这通过公式 V(G) = E - N + 2 计算,其中 E 是代码控制流图中的边数,N 是节点数。
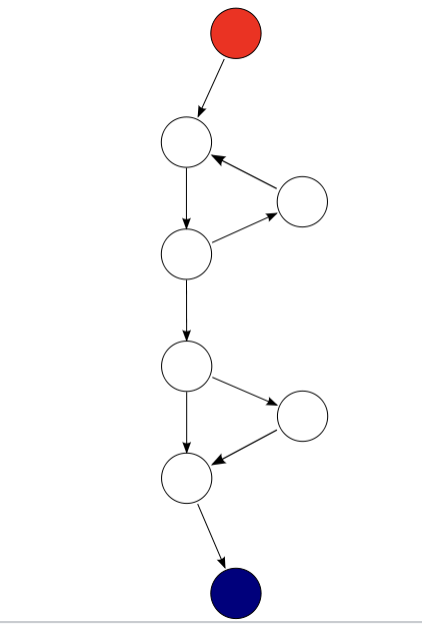
假设我们有一个具有上述流图的函数,我们可以计算圈复杂度为 V(G) = 9(边)- 8(节点)+ 2 = 3。因此,当决策点数量增加而节点数量不变时,我们说它在圈复杂度指标上更复杂。
简单来说,我们可以通过计算抽象在执行时可以走的独立流路径(决策点)来计算圈复杂度。
代码示例
1 | function makeConditionalState(x){ |
1 | ○ // Entry |
这个程序中条件语句 if(x) 的存在创建了一条决策路径,导致圈复杂度为 2。
问题的说明
圈复杂度是衡量代码复杂度的有用指标,但它也有其局限性。让我们来看两个例子:
1 | function sumOfPrimes(max) { // +1 |
1 | function getWords(number) { // +1 |
虽然圈复杂度对 sumOfPrimes 和 getWords 方法赋予了相同的权重,但显然 sumOfPrimes 比 getWords 复杂得多,也更难理解。这说明仅仅基于程序的路径来衡量可理解性可能是不够的。
认知复杂度
认知复杂度是比圈复杂度更全面的指标,因为它不仅衡量控制流结构的数量,还衡量它们之间的相互作用以及理解代码所需的心智努力。它根据每个控制流结构的复杂性及其与其他结构的交互,为其分配一个认知权重,从而更准确地评估代码的可读性和可维护性。这很重要,因为某些代码结构(如嵌套循环和条件语句)比其他结构更难让人理解和推理。
基本标准和方法
认知复杂度分数根据三条基本规则进行评估:
- 忽略允许将多个语句简洁地合并为一个的结构
- 对代码线性流程中的每个中断增加(加一)
- 当流程中断结构嵌套时增加
此外,复杂度分数由四种不同类型的增量构成:
- 嵌套增量 - 用于评估控制流结构相互嵌套的情况
- 结构增量 - 用于评估受嵌套增量影响且会增加嵌套计数的控制流结构
- 基础增量 - 用于评估不受嵌套增量影响的语句
- 混合增量 - 用于评估不受嵌套增量影响但会增加嵌套计数的控制流结构
这些规则及其背后的原则将在以下部分进一步详细说明。
忽略简写
认知复杂度制定的一个指导原则是,它应该激励良好的编码实践。也就是说,它应该忽略或减少对让代码更具可读性的特性的惩罚。
空值合并
1 | // bad practice |
认知复杂度会忽略空值合并(null-coalescing),以激励良好的编码实践。
对线性流程中断的增量
认知复杂度制定的另一个指导原则是,打断代码从上到下、从左到右正常线性流程的结构需要维护者付出更多努力来理解代码。
其中一些包括:
- 循环结构:for、while、do while……
- 条件语句:三元运算符、if、#if、#ifdef……
Catch 语句
1 | try { // +1 |
try...catch 对复杂度的贡献与 if...else 非常相似。因此它也会增加认知复杂度。
Switch 语句
一个 switch 及其所有 case 合并在一起只产生一个结构增量。这与圈复杂度不同,圈复杂度对每个 case 都产生增量。
但从维护者的角度来看,带有 case 的 switch 比 if...else if 链要容易理解得多。
1 | function getAnimalSound(animal) { |
使用 switch 时,我们只需将一个变量与一组具名字面量值进行比较,使其更易于理解和维护。
逻辑运算符序列
1 | a && b |
理解前两行并不难。另一方面,理解第三行所需的努力明显不同。
当混合使用运算符时,布尔表达式会变得更难理解。
1 | if (a // +1 `if` |
递归
与圈复杂度不同,认知复杂度对递归调用链中的每个方法(无论是直接还是间接递归)都添加一个基础增量。因为递归对复杂度的贡献与循环非常相似。
对嵌套流程中断结构的增量
嵌套的流程中断会大幅增加代码复杂度,五层嵌套的 if...else 比同样五个线性的 if...else 序列要难理解得多。
1 | void myMethod () { |
直觉上”正确”的复杂度分数
让我们回顾第一个例子,在那个例子中圈复杂度给出了相同的分数。
1 | function sumOfPrimes(max) { |
1 | function getWords(number) { |
认知复杂度算法为这两个方法给出了明显不同的分数,更真实地反映了它们相对的可理解程度。
在方法级别以上也有价值的指标
使用圈复杂度时,很难区分一个拥有大量简单 getter 和 setter 的类与一个包含复杂控制流的类,因为两者可以拥有相同数量的决策点。然而,认知复杂度通过不对方法结构本身计数来解决这一限制,使得比较不同类的指标值变得更容易。因此,可以区分具有简单结构的类与包含复杂控制流的类,从而更好地识别程序中可能难以理解和维护的区域。
行业标准
| 圈复杂度 | 代码质量 | 可读性 | 可维护性 |
|---|---|---|---|
| 1-10 | 清晰且结构良好 | 高 | 低 |
| 11-20 | 较为复杂 | 中 | 一般 |
| 21-50 | 复杂 | 低 | 困难 |
| 51+ | 非常复杂 | 差 | 非常困难 |
| 认知复杂度 | 代码质量 | 可读性 | 可维护性 |
|---|---|---|---|
| 1-5 | 简单易懂 | 高 | 容易 |
| 6-10 | 较为复杂 | 中 | 一般 |
| 11-20 | 复杂 | 低 | 困难 |
| 21+ | 非常复杂 | 差 | 非常困难 |
使用 ESLint 为你的代码设置复杂度指标
使用 ESLint 是管理代码复杂度指标的一种有效方式。ESLint 是一款流行的代码检查工具,可以帮助检测和报告各种代码问题,包括圈复杂度和认知复杂度。
圈复杂度
要设置 ESLint 报告圈复杂度,你可以使用 eslint-plugin-complexity 插件,它提供了一个可配置的规则,用于强制执行最大圈复杂度阈值。首先,你需要通过运行 npm install eslint-plugin-complexity 来安装插件。然后,你可以将插件添加到你的 ESLint 配置文件中并配置最大阈值:
1 | { |
在这个例子中,我们将最大阈值设置为 10。如果一个函数或方法的圈复杂度超过此阈值,ESLint 将报告错误。
认知复杂度
要设置 ESLint 报告认知复杂度,你可以使用 eslint-plugin-cognitive-complexity 插件,它提供了一个可配置的规则,用于强制执行最大认知复杂度阈值。首先,你需要通过运行 npm install eslint-plugin-cognitive-complexity 来安装插件。然后,你可以将插件添加到你的 ESLint 配置文件中并配置最大阈值:
1 | { |
在这个例子中,我们将最大阈值设置为 15。如果一个函数或方法的认知复杂度超过此阈值,ESLint 将报告错误。
通过在 ESLint 中设置这些指标,你可以主动监控和管理代码的复杂度,使其随着时间的推移更易于理解和维护。
总结
总之,代码复杂度是一个关键因素,会对工作效率和项目可维护性产生重大影响。使用圈复杂度和认知复杂度指标可以帮助衡量和管理代码复杂度,使开发者能够识别潜在的问题区域,并优化代码的可读性和可维护性。
降低代码复杂度有多种方法,例如使用设计模式和应用 TDD(Testing Best Practice Tdd)。总体而言,通过理解和管理代码复杂度,开发者可以构建更好、更易维护的软件,从而提供价值并满足用户需求。