软件测试是一件困难的事情。好的测试用例可以帮助你提升代码的可维护性和稳定性,而糟糕的测试用例不仅无法带来收益,某些情况下甚至会拖慢你的开发进程。
很高兴看到我们团队现在写了很多测试用例,但其中有些并没有真正使团队受益,甚至成了开发的负担。我认为部分原因是我们缺乏关于如何设计真正有用的好测试用例的指导。因此,我想为如何在单元测试(UT)和端到端测试(E2E)中编写测试用例建立一个基本框架。
为了理解这些框架为何如此构建,我们首先需要学习测试的通用知识。我们稍后会讨论这个问题。
为什么我们需要测试?
为了编写好的测试用例,我们需要理解我们的目标。在开发软件时,我们需要测试的原因有很多。以下是最显而易见的一个:
- 免受 Bug 侵害:确保我们的软件今天是正确的,在未知的未来也是正确的。
随着软件的增长,你将不可避免地需要验证越来越多的逻辑,以确保你对代码的修改是正确的,并且不会意外破坏已有的功能。自动化测试是降低验证成本的好方法。
为什么软件测试很难?
软件测试的核心挑战有两点:
- 可能的测试用例空间通常太大,无法穷举覆盖。假设我们要测试一个 32 位浮点乘法操作 a*b,就有 2^64 个测试用例!
- 软件行为在可能输入的空间上是非连续且离散变化的。例如,如果我们要测试 abs(a) 函数,当 a < 0 和 a >= 0 时它的行为是不同的。
系统在广泛的输入范围内看似运行正常,却可能在某个单一边界点上突然失败。
因此,测试用例必须经过仔细和系统地选择。
热身:为乘法函数设计测试用例
1 | /** |
什么是这个函数的好的测试套件?
系统性测试
系统性测试意味着我们以有原则的方式选择测试用例,目标是设计一个具有三个理想属性的测试套件:
- 正确(Correct):一个正确的测试套件应接受规格说明的所有合法实现。这让我们可以自由地在内部修改实现,而无需修改测试套件。
- 充分(Thorough):一个充分的测试套件能尽可能多地发现实现中的实际 Bug。
- 精简(Small):我们希望在保持充分性的同时编写更少的测试用例。
通过分区选择测试用例
软件通常有大范围的输入值,在不同范围内产生不同的行为。我们希望选择一组测试用例,既足够精简以便于编写、维护和快速运行,又足够充分以发现程序中的 Bug。
为此,我们将输入空间划分为分区(partitions),每个分区包含一组输入。
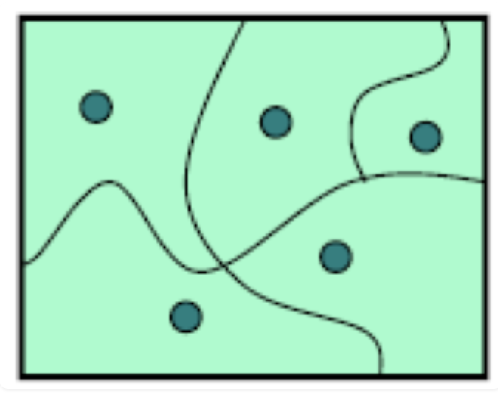
然后我们从每个分区中选择一个测试用例,这就构成了我们的测试套件。
分区背后的思想是将输入空间划分为若干组相似的输入,程序在这些输入上具有相似的行为。
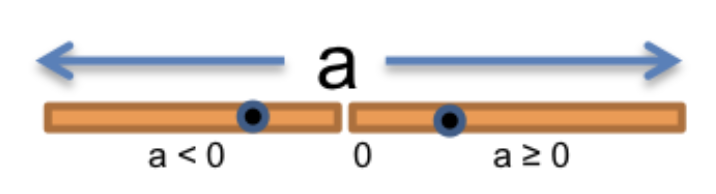
让我们看看 abs(a) 函数:
1 | /** |
我们关注该函数在输入空间中会产生不同行为的地方:
- 当
a >= 0时,abs()返回a。 - 当
a < 0时,abs()返回-a。
因此我们可以将输入空间 a: number 划分为 a < 0 和 a >= 0 两个分区,如下所示:
然后我们从每个分区中选取一个测试用例,构成我们的测试套件:
1 | // case 1: negative input |
在分区中包含边界值
Bug 往往发生在分区之间的边界处。一些例子:
- 0 是正数和负数之间的边界
- 数值类型的最大值和最小值,如
Number.MAX_SAFE_INTEGER或Number.MAX_VALUE - 集合类型的空值,如空字符串、空数组或空集合
- 序列(如字符串或数组)的第一个和最后一个元素
为什么这些边界值危险?主要有两个原因:
- **程序员经常犯”差一错误(off-by-one)”**,比如写
<=而不是<,或者将计数器初始化为 0 而不是 1。 - 边界可能是代码行为不连续的地方:例如,当用作整数的数值变量超过
Number.MAX_SAFE_INTEGER时,它会突然开始失去精度。
因此,我们可以在 abs() 测试套件中添加另一个测试用例:
1 | // case 1: negative input |
在同一测试用例中覆盖多个分区
在前面的例子中,我们从一个分区中选取一个输入作为一个测试用例。这很好。但随着程序变得更加复杂,存在多个输入维度时,我们可能会面临这样的问题:即使每个分区只选取一个测试用例,输入的组合数量仍然非常庞大,从而打破了我们希望测试套件精简且快速的原则。
1 | Let's take a look at the multiply example: |
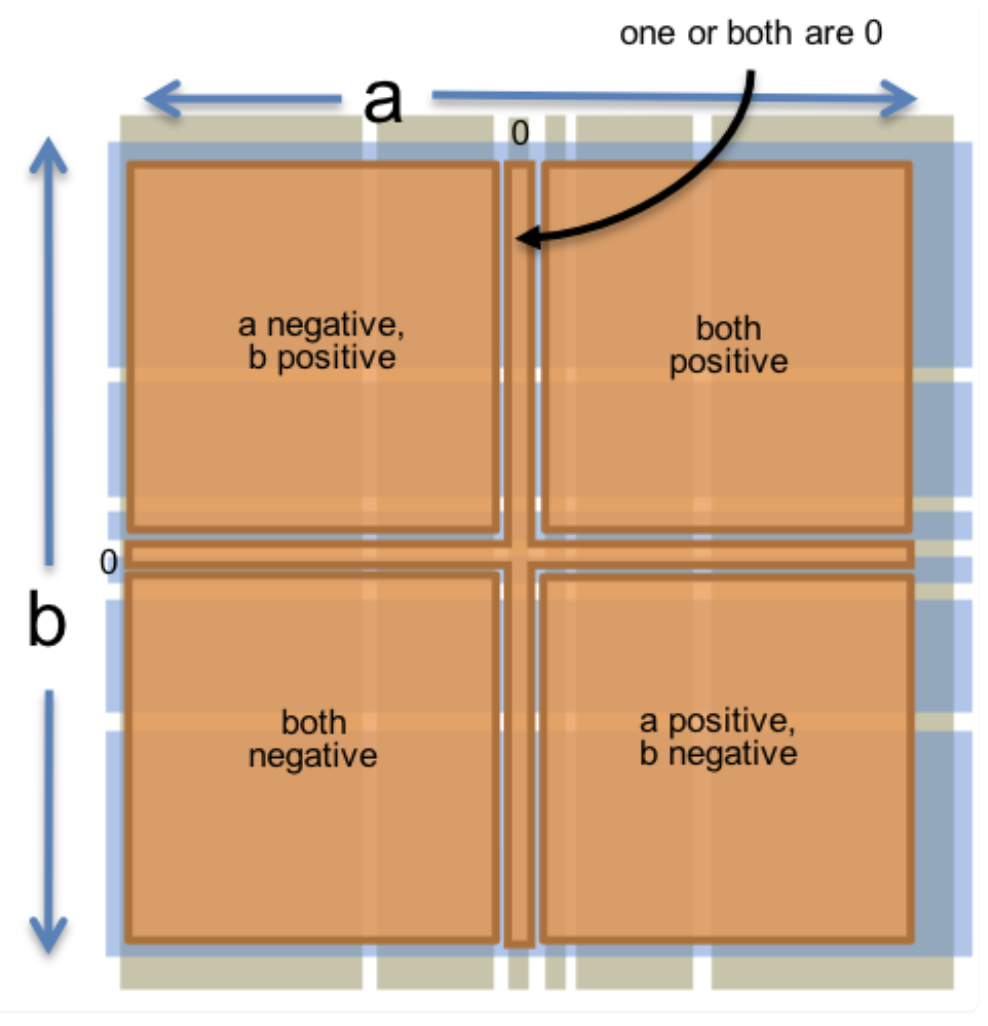
这个函数有一个二维输入空间,由所有整数对 (a, b) 组成。根据乘法规则,我们可以将输入空间划分为以下分区:
- a 和 b 都是正数,结果为正数
- a 和 b 都是负数,结果为正数
- a 为正数,b 为负数,结果为负数
- a 为负数,b 为正数,结果为负数
然后,我们添加边界情况:
- a 或 b 为 0,因为结果始终为 0
- a 或 b 为 1,即乘法的单位元素
为了确保输入数字很大时也能正常工作,我们还需要测试 Number.MAX_SAFE_INTEGER、Number.MIN_SAFE_INTEGER。因此我们有: - a 或 b 是小数或大数(即小到可以精确表示为数值,或大到超出数值范围)
将每个维度分别划分为:
- 0
- 1
- 小正整数(≤ Number.MAX_SAFE_INTEGER 且 > 1)
- 小负整数(≥ Number.MIN_SAFE_INTEGER 且 < 0)
- 大正整数(> Number.MAX_SAFE_INTEGER)
- 大负整数(< Number.MIN_SAFE_INTEGER)
最终我们得到一个复杂的分区图,如下所示:
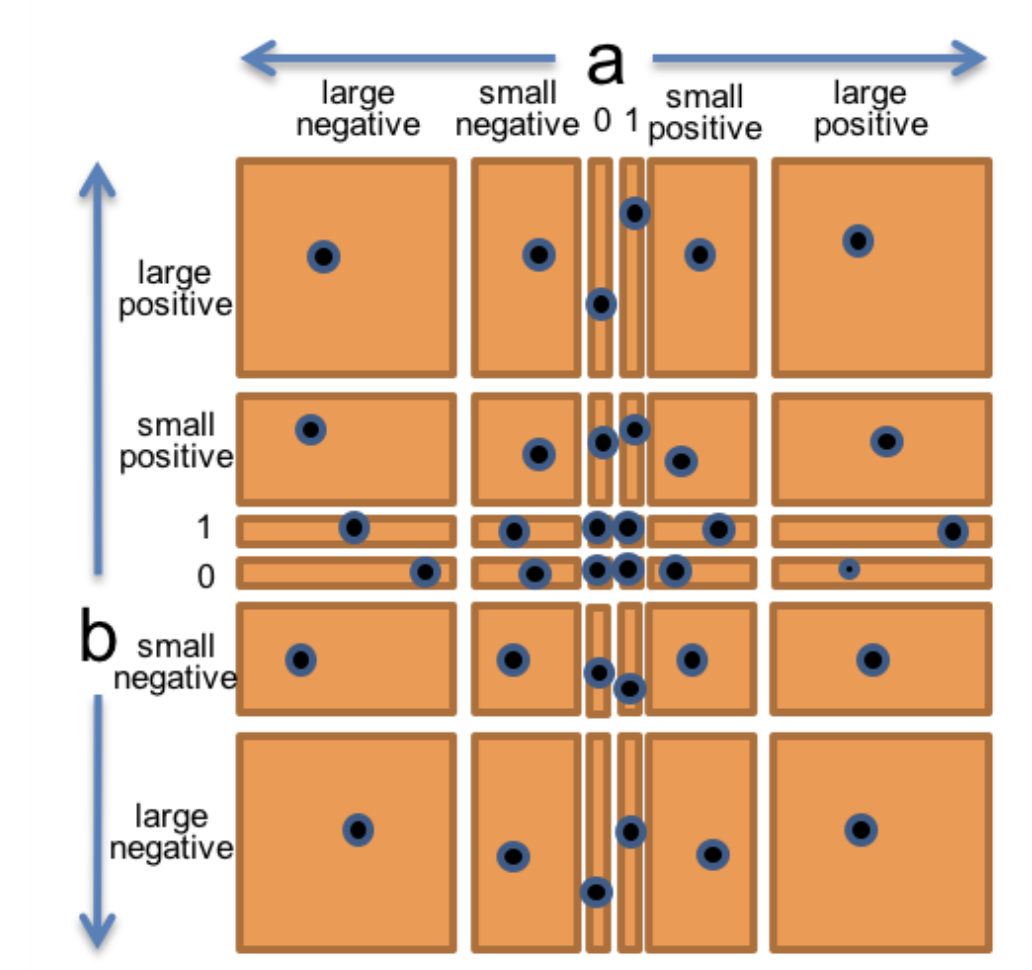
如果我们为每个分区选取一个测试用例(图中的点),共有 36 种组合。这太多了!这就是所谓的组合爆炸。而这仅仅是两个维度。
如何解决?我们意识到测试用例的数量随维度增加而增加:O(n) = s^n,其中 s 是每个维度的分区数,n 是维度数量。并且从单个维度的角度来看,我们在重复覆盖相同的分区。因此,我们可以将每个输入 a 和 b 的特征视为输入空间的两个独立分区,每个分区只考虑一个值:
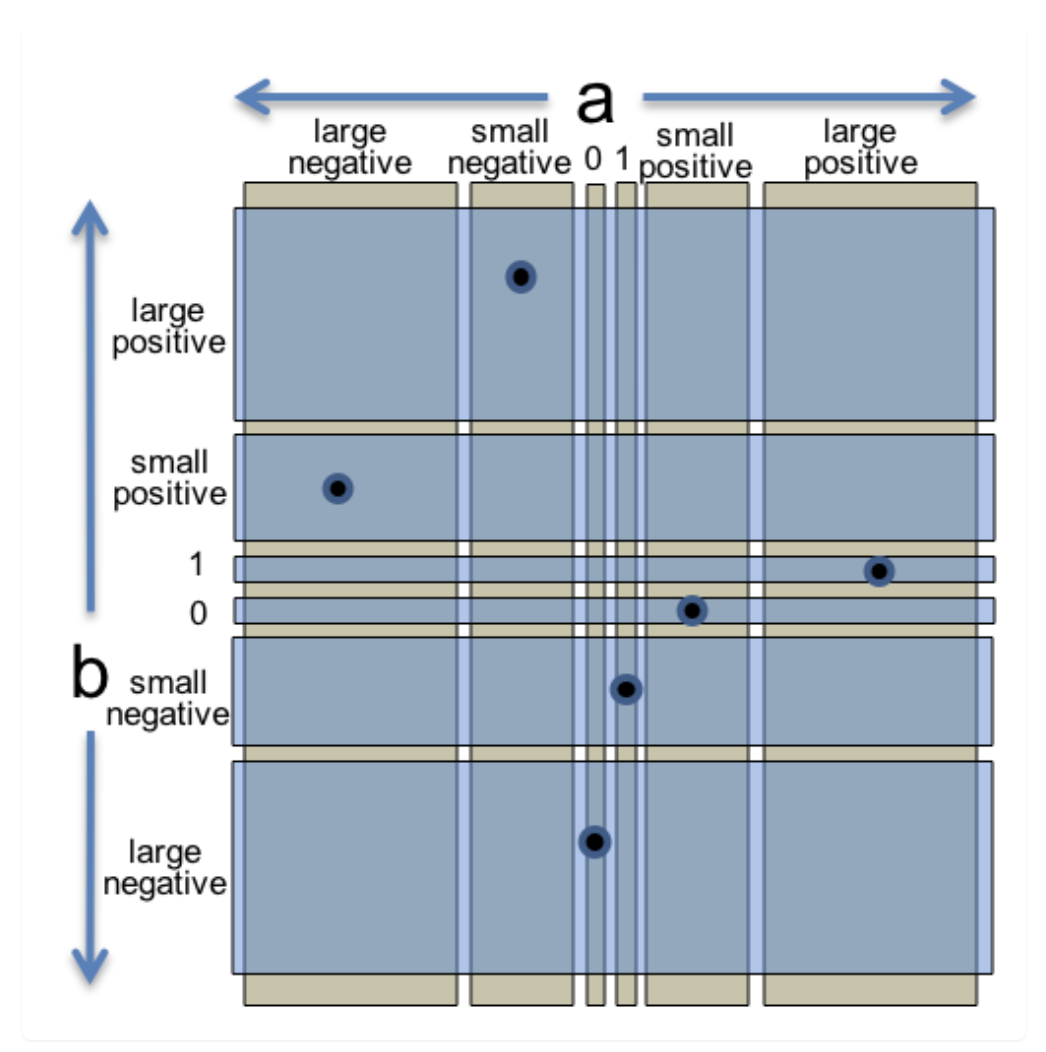
1 | // partition on a: |
然后我们将这些值组合在一起,不重复地覆盖每个维度的所有分区,且随着维度增加,复杂度不会增加:O(n) = s。
这确实增加了遗漏 Bug 的风险,但我们可以添加另一层分区来覆盖部分组合:
1 | // a and b are both positive, a is a small integer, b is a LARGE_NUMBER |