TL;DR: Vibe Coding(氛围编码)让 AI 自由发挥,速度快但不可控;Spec-Driven Coding 通过持久化的规范文件约束 AI 行为,实现可预测、可追溯的输出。本文用 OpenSpec + Claude Code 的实践经验,拆解两种模式的差异和适用场景。
背景与目标
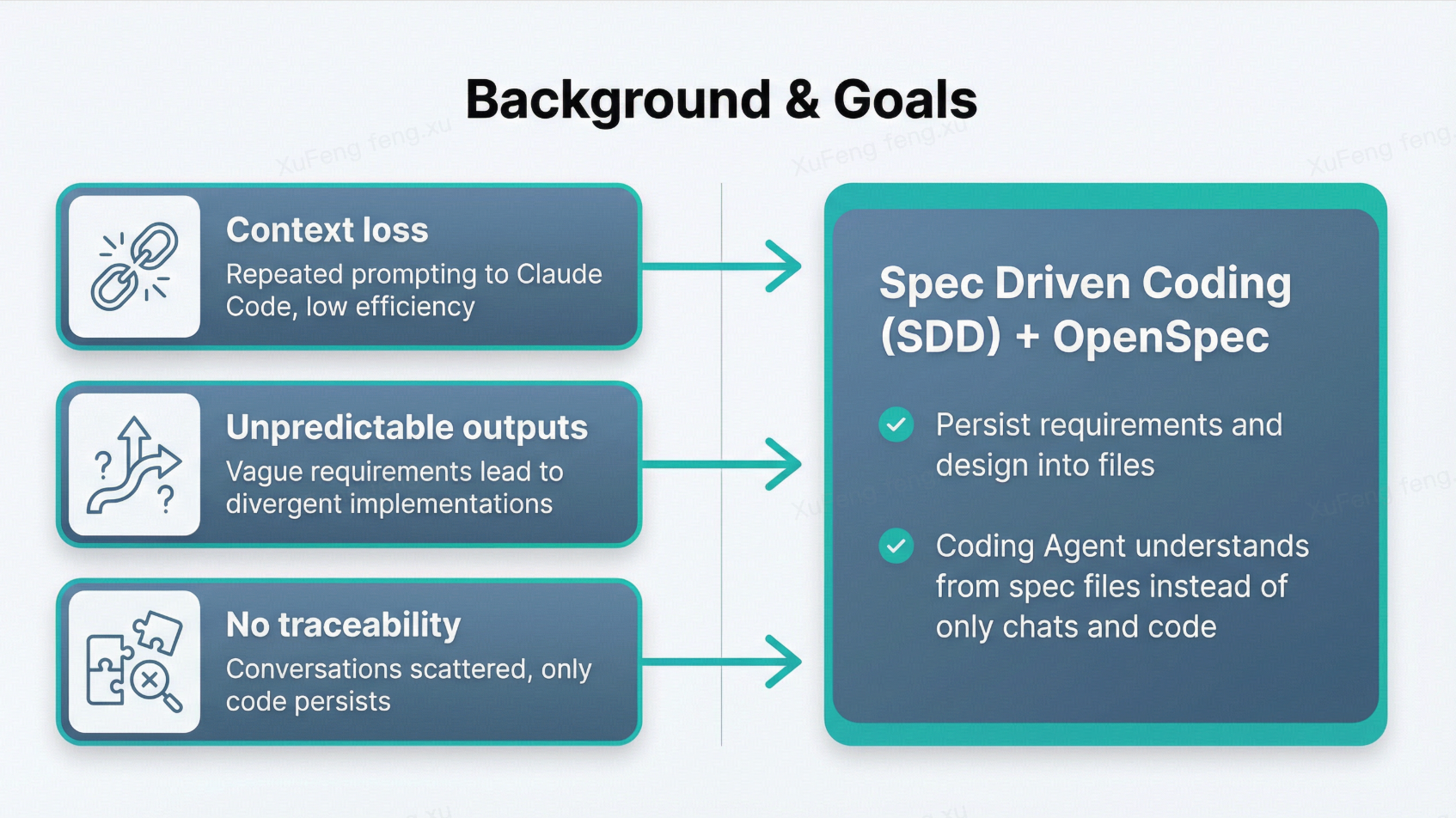
我目前主要用 Claude Code 完成需求理解、技术设计和代码实现。在大量使用 Vibe Coding 的过程中,我遇到了三个核心痛点:
- 上下文丢失 — 每次新对话都要重复喂需求文档、设计方案和仓库知识,效率极低。
- 产出不可预测 — 同样的需求,由于对话中描述往往比较模糊,AI 会自由发挥,给出完全不同的实现。
- 缺乏可追溯性 — 做完一个功能后,所有思考和对话只留在聊天记录里,唯一持久化的产物是代码本身。
Spec-Driven Development(SDD)的核心思路是:把需求、设计、决策从聊天记录中”提取”出来,用定义清晰的框架持久化成文件。AI 从结构化的规范文件中理解项目和需求,远比从零散的聊天记录和代码中理解靠谱。
经过调研,我选择了 OpenSpec 作为 SDD 框架——它轻量、增量化、易上手。
OpenSpec 核心原理:三层结构
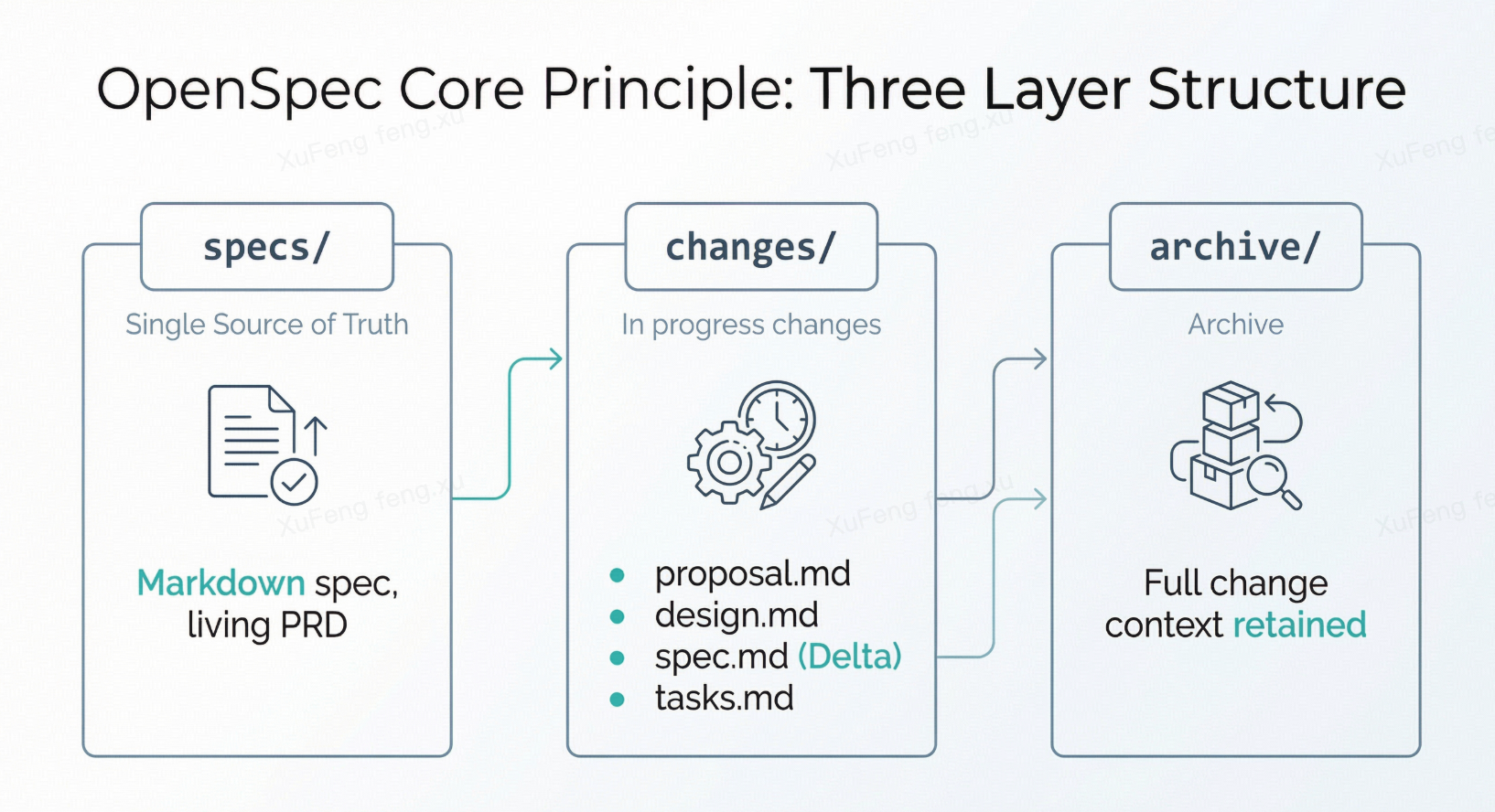
整个机制围绕一个 openspec/ 目录展开:
specs/ — 系统的”单一事实源”。用 Markdown 描述系统当前的行为规范。这不是代码,而是”系统应该怎么工作”的契约,类似一份活的、版本化的 PRD。
changes/ — 进行中的变更。每个功能或修复对应一个子目录,包含四个核心产物:
proposal.md— 为什么做design.md— 怎么做spec.md— 增量规范(Delta Spec)tasks.md— 执行清单
这些文件就是你给 AI 的”施工图纸”。
archive/ — 已完成变更的归档。相当于架构决策记录(ADR),变更的完整上下文永久保留。
最关键的概念:Delta Specs

这是 OpenSpec 最有价值的设计。你不需要每次重写整个系统规范,只需要在 changes/ 里用 ADDED、MODIFIED、REMOVED 标记本次变更对主规范的影响。归档时自动合并回 specs/。
这和写代码的 diff-patch 思路完全一致,对存量项目特别友好。
OpenSpec + Claude Code 开发流程
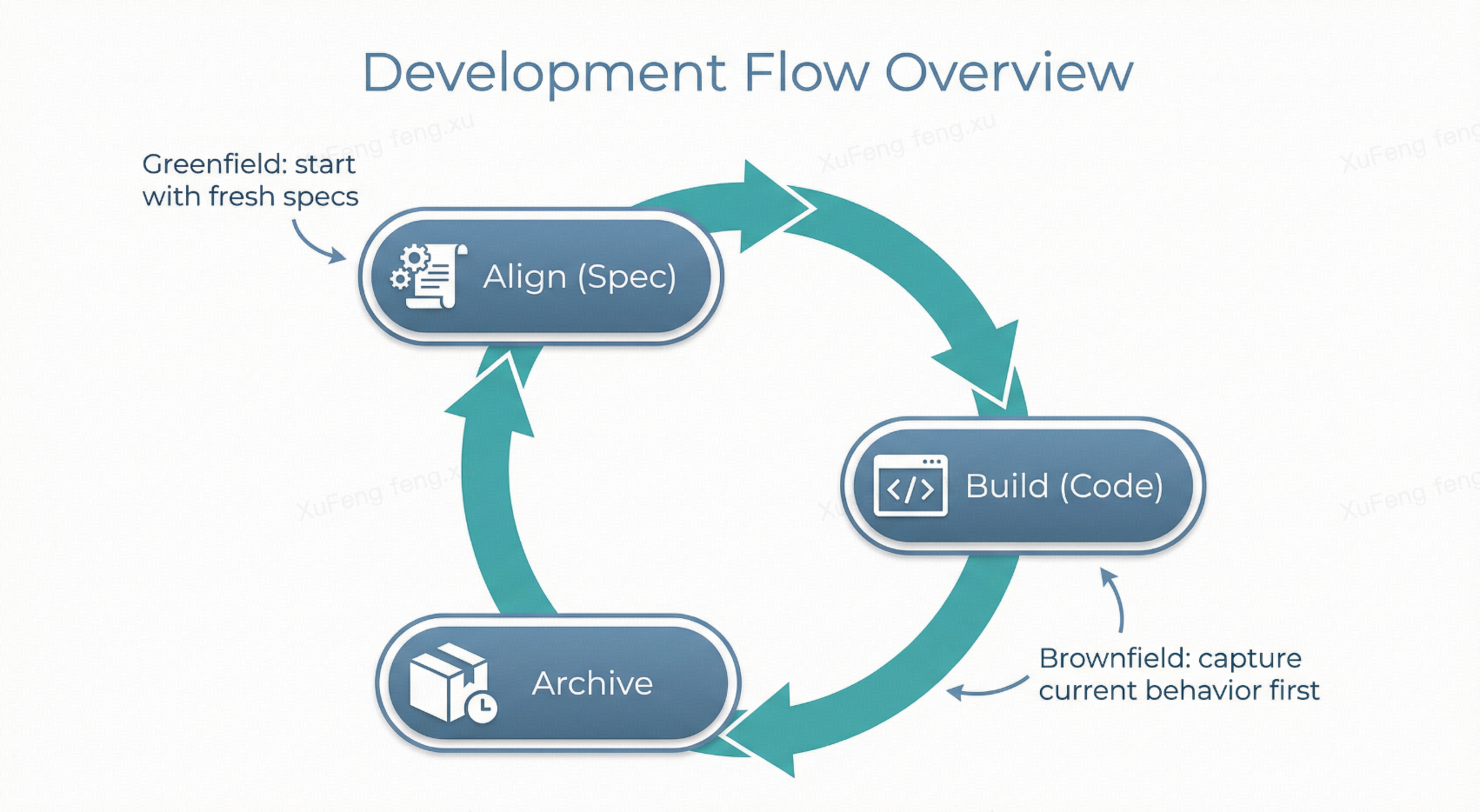
无论是新系统还是存量系统,底层都遵循同一个流程:对齐(Spec)→ 施工(Code)→ 沉淀(Archive)。
区别在于起点不同:新系统从零建 specs;存量系统先把现有行为”捕获”进 specs,然后用 Delta Specs 做增量变更。
场景一:新系统(Greenfield)
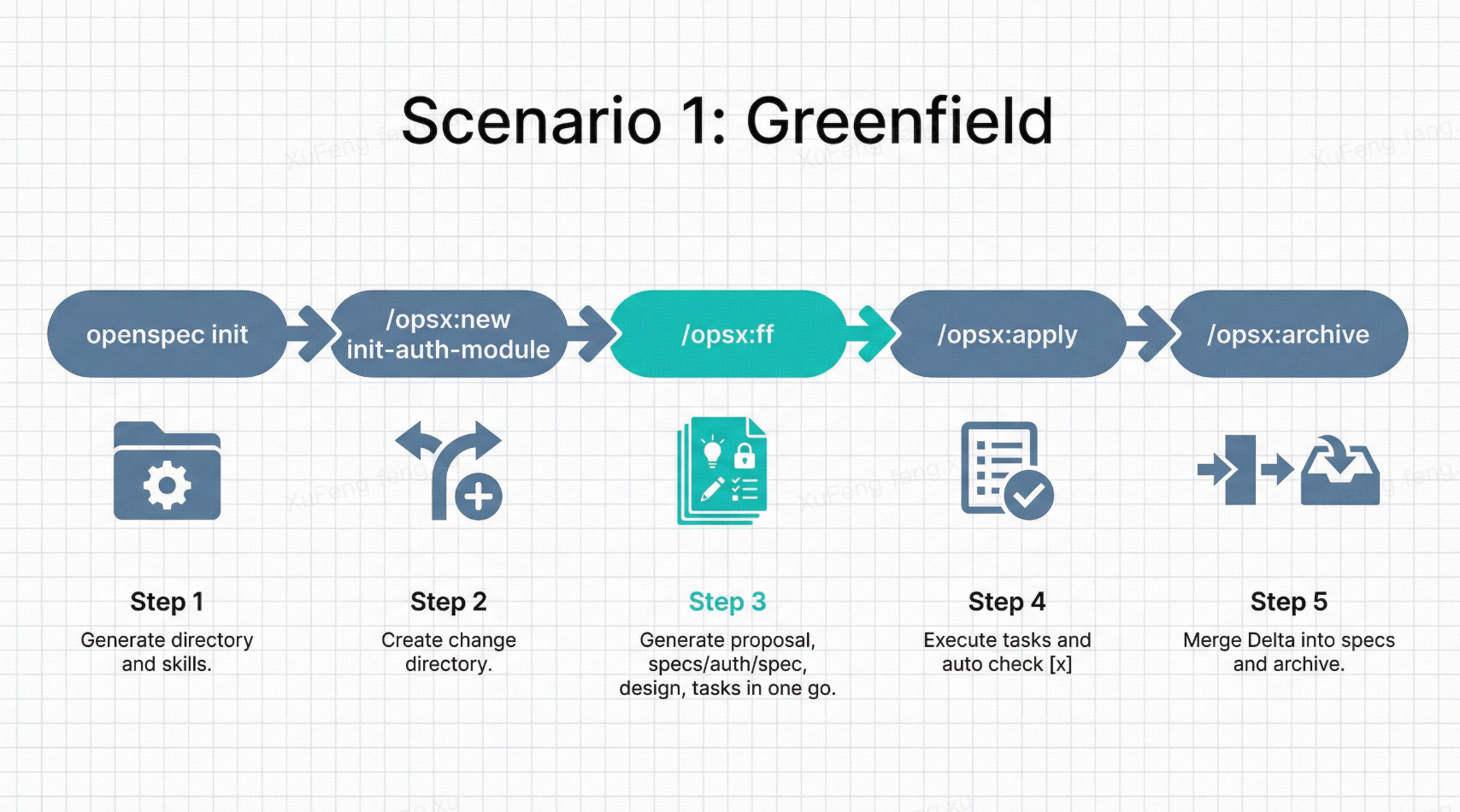
假设你要从零搭建一个运营管理后台。
第一步:初始化
1 | cd your-new-project |
这会生成 openspec/ 目录结构,并在 .claude/ 下注入技能文件,让 Claude Code 理解 /opsx:* 命令。此时 specs/ 是空的。
第二步:定义第一个变更
1 | /opsx:new init-auth-module |
Claude Code 创建 openspec/changes/init-auth-module/ 目录。
第三步:生成规划产物
需求清晰的话直接快进:
1 | /opsx:ff |
Claude Code 一次性生成四个文件:
- proposal.md — 认证模块的目标、范围、风险
- specs/auth/spec.md — 用 GIVEN-WHEN-THEN 场景定义行为
- design.md — 技术方案(如”用 NextAuth.js,session 存 Redis”)
- tasks.md — 执行清单,拆到文件级别
你审查这四个文件,发现 design 的方案不合适?直接改文件或跟 Claude Code 对话调整。
第四步:AI 执行编码
1 | /opsx:apply |
Claude Code 读取 tasks.md,逐条创建文件、写代码、改配置。每完成一条自动打勾 [x]。你像项目经理一样看着它施工,有问题随时喊停。
第五步:归档
1 | /opsx:archive |
增量规范合并到 openspec/specs/auth/spec.md,变更目录整体移入 archive/。此时 specs/ 有了系统的第一份行为规范。
后续每个新模块重复这个循环。每次 archive 后 specs/ 就多一份领域规范,系统的”事实源”逐步丰满。
新系统的特点是:前几个变更的 spec 几乎全是 ADDED。随着系统长大,后续变更会越来越多出现 MODIFIED 和 REMOVED,逐渐过渡到存量系统的模式。
场景二:存量系统(Brownfield)
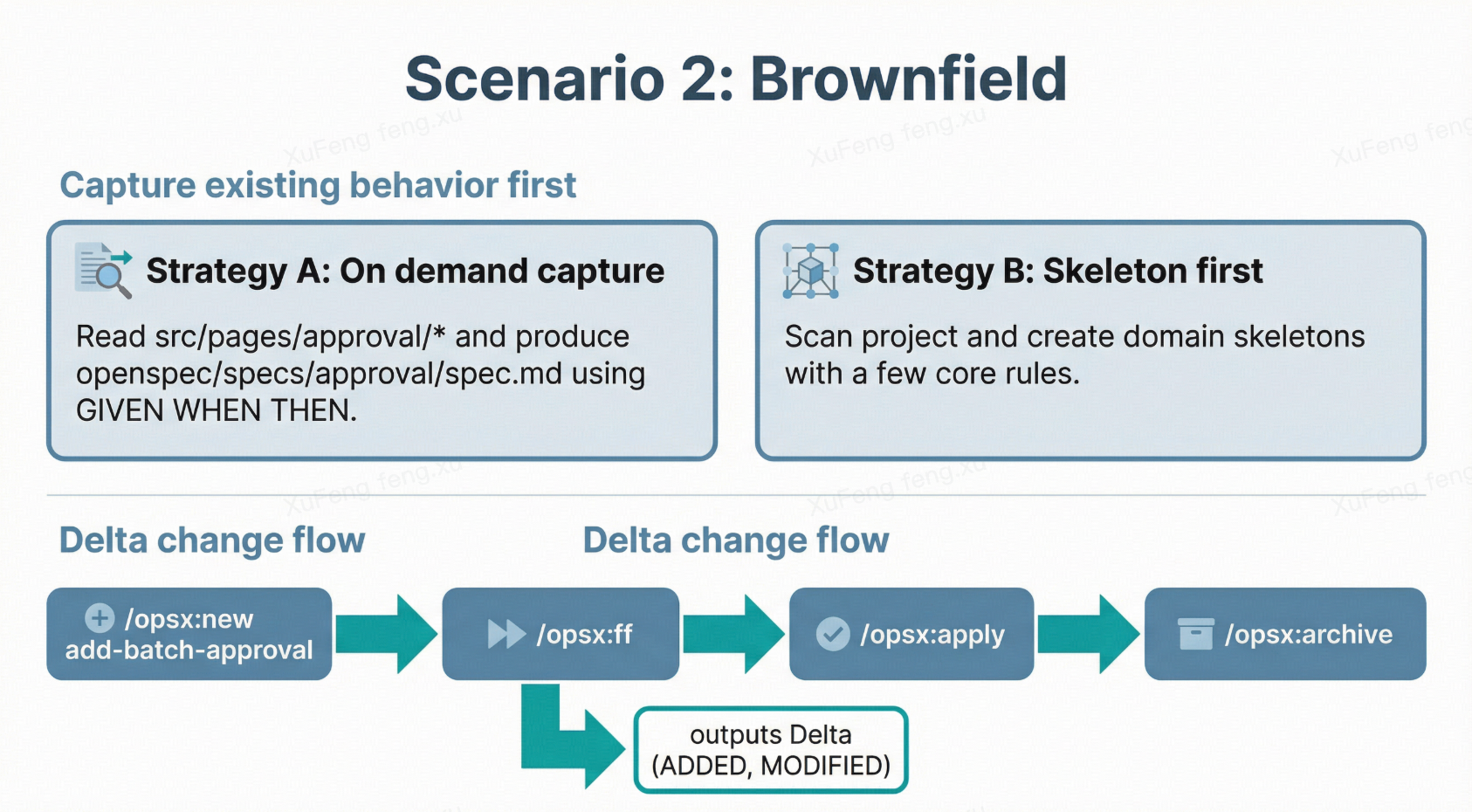
更常见的场景——某个平台已经跑了很久,现在要加新功能或改已有逻辑。
关键区别:你需要先”捕获”现有行为。
存量系统的 specs/ 一开始也是空的,但系统已经有大量已存在的行为。你有两个策略:
策略 A:按需补录(推荐)
不需要一次性把整个系统写成 spec。只在你要改某个模块时,先让 Claude Code 帮你把该模块的现有行为”捕获”进 specs:
1 | 我要改动审批中心模块。请先阅读 src/pages/approval/ 下的代码, |
Claude Code 读代码,产出一份描述现状的 spec。你审查确认后,就成了这个模块的基线。
策略 B:先写骨架再逐步细化
让 Claude Code 扫描整个项目结构,生成骨架级的 specs 目录,每个领域只写最核心的几条规范。后续变更时再补充细节。
然后进入正常变更流程。假设要给审批中心加”批量审批”功能:
1 | /opsx:new add-batch-approval |
这次生成的 spec 就是 Delta Spec——不重写整个审批规范,只描述增量:
1 | ## ADDED Requirements |
只有 ADDED 和 MODIFIED 的部分,其他现有行为完全不碰。这就是 Delta Specs 对存量系统的价值——改动范围被精确控制。
/opsx:apply 时 Claude Code 也只改相关文件,不会动你没提到的模块。/opsx:archive 后增量自动 merge 回主规范,基线更新。
日常使用经验
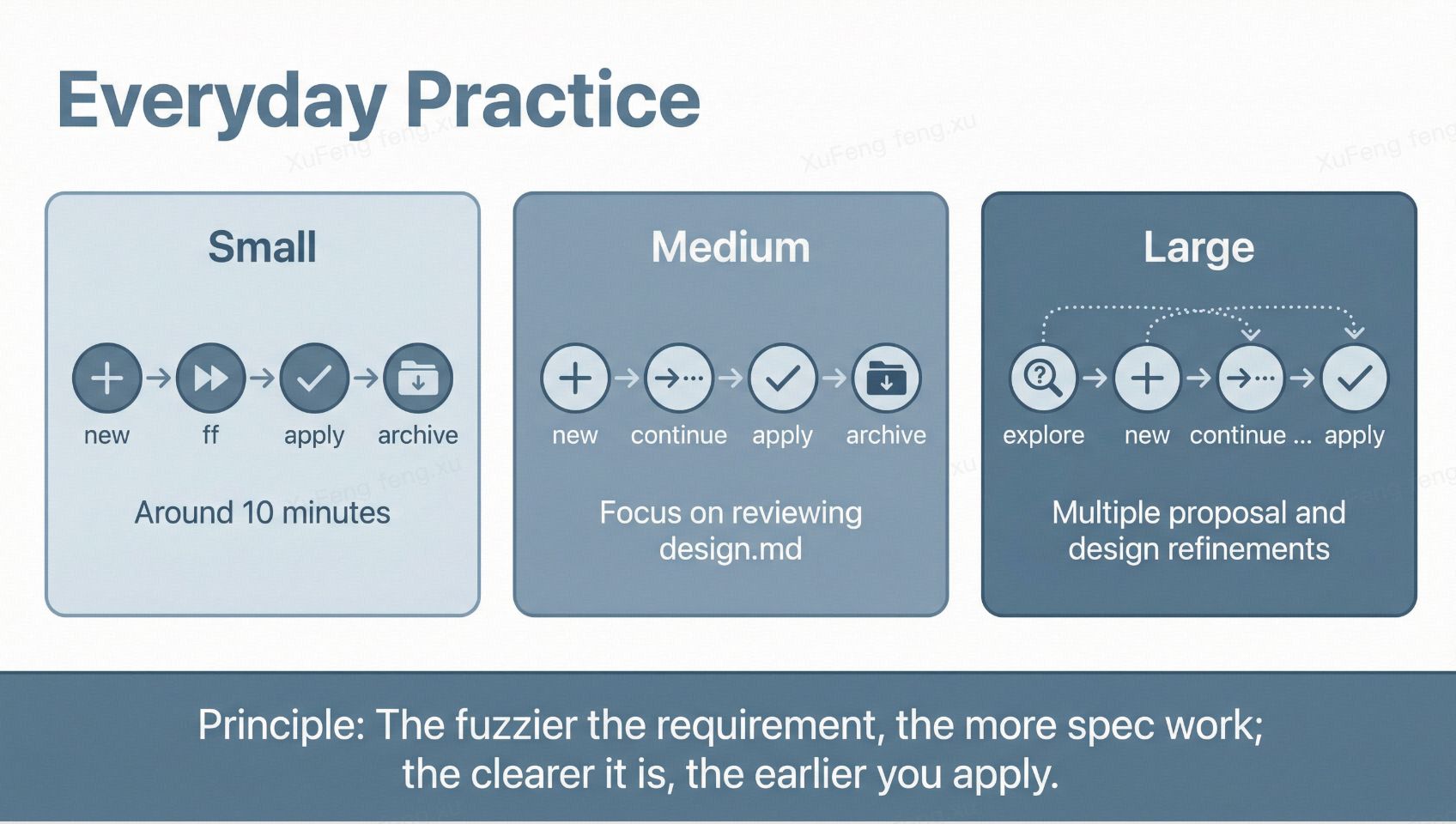
根据需求规模选择不同深度:
小需求(bug 修复、UI 微调):new → ff → apply → archive,快进模式,十分钟内走完。
中等需求(新增子功能):new → continue(逐步生成,每步审查)→ apply → archive,重点审查 design.md 的技术方案。
大需求(新模块、重构):先 explore 让 Claude Code 分析现有代码和可选方案,再 new → continue → continue → ...,proposal 和 design 可能要经过几轮修改,最后才 apply。
核心原则:需求越模糊,在 spec 层花的时间越多;需求越清晰,越早进入 apply。 OpenSpec 的灵活性在于它不强制你走完每一步,而是让你根据实际情况选择合适的深度。