While relearning JavaScript, I got stuck on a basic-sounding question: when we say JavaScript “runs,” how much of it has already been compiled?
The yes/no answer was less interesting than the ambiguity in the word “compiled.” In frontend engineering, compilation usually means TypeScript, Babel, SWC, or esbuild. Inside a JavaScript engine, it means parsing, bytecode, JIT, and optimized machine code. Same word, different layer.
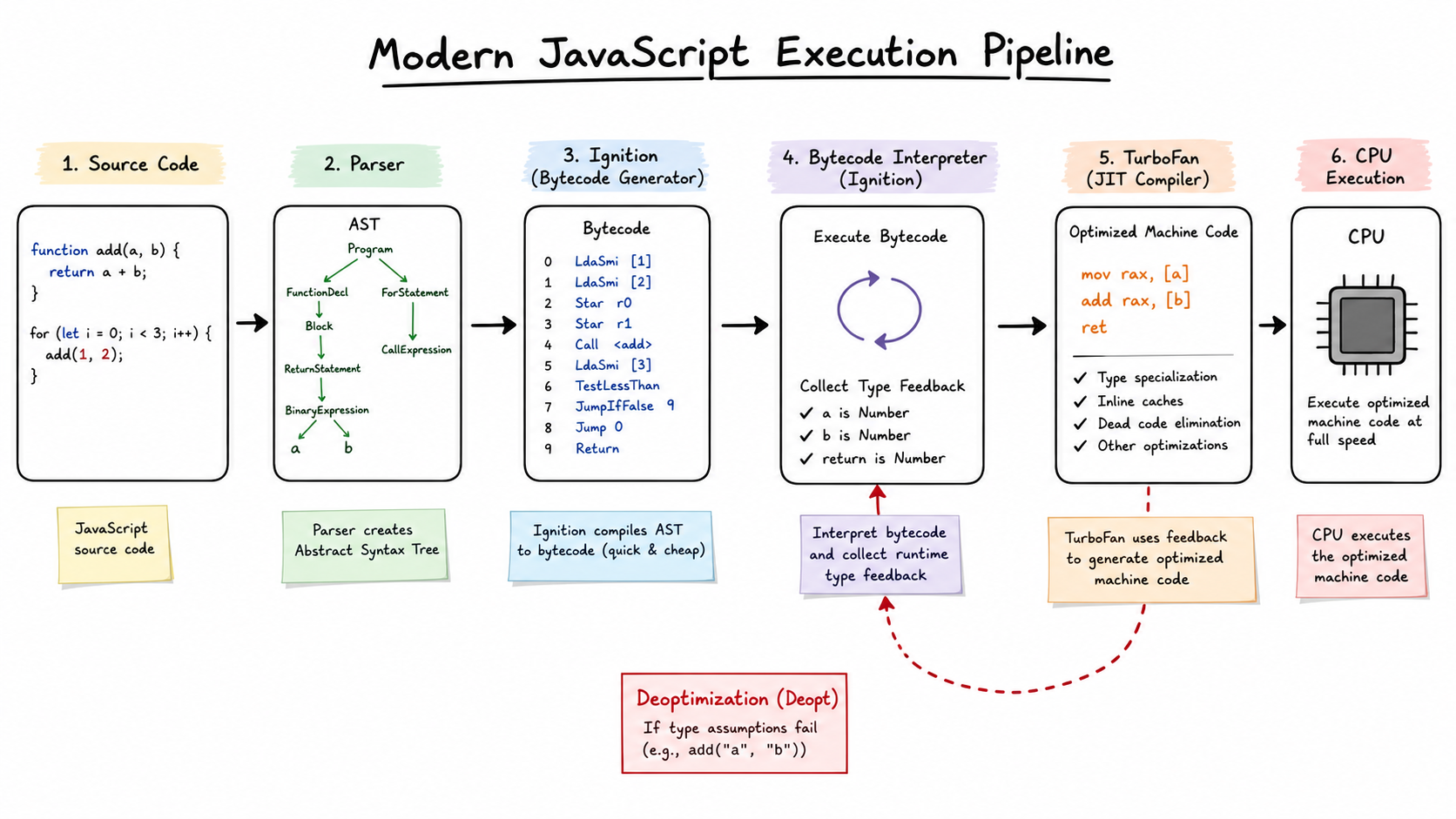
Figure: Modern JavaScript execution in V8. Source code becomes AST and bytecode first; runtime type feedback lets TurboFan compile hot paths into optimized machine code. generated by gpt-image-2.
Build-time compilation is not what the browser cares about
The compilation frontend developers usually touch happens at build time.
For example, TypeScript:
1 | const user: User = getUser(); |
eventually becomes JavaScript:
1 | const user = getUser(); |
Or optional chaining:
1 | const city = user?.address?.city; |
Babel may lower it into plain JavaScript that works in older runtimes.
This layer is handled by TypeScript, Babel, SWC, esbuild, and similar tools. It solves engineering problems: type erasure, syntax lowering, bundling, minification, and compatibility.
The browser does not care whether the source was TypeScript or which bundler produced it. The browser receives JavaScript.
The browser still compiles JavaScript at runtime
Modern JavaScript engines usually do not execute source code line by line.
In Chrome’s V8, a more realistic path is this: the parser turns source code into an AST; Ignition generates and executes bytecode; while the program runs, the engine collects type feedback; if a function becomes hot enough, TurboFan compiles it into optimized machine code.
There are two key pieces here:
| Component | Role |
|---|---|
| Ignition | V8’s interpreter. It generates and executes bytecode. |
| TurboFan | V8’s optimizing compiler. It compiles hot code into optimized machine code. |
So a better mental model is not simply “JavaScript is interpreted.” Modern JavaScript is a dynamic language running on an interpreter plus a JIT compiler.
The old description was historically reasonable. Early browsers were much closer to source interpretation.
But modern Chrome, Safari, Firefox, and Node are not that simple. Node uses V8 too, so node server.js also goes through parsing, bytecode, and JIT optimization.
Does the browser host get compiled too?
The wording matters here.
The JavaScript engine compiles your JavaScript code. Browser-host APIs such as DOM, timers, networking, and storage are mostly native browser capabilities implemented in languages such as C++, Rust, or Objective-C, then exposed to JavaScript through bindings.
So your JavaScript is handled by the JS engine. APIs such as document, fetch, and setTimeout are host capabilities surfaced to JavaScript.
When you write:
1 | document.querySelector("#app"); |
the engine executes the JavaScript call path, but the real DOM query is not a separate DOM API JavaScript source file being JIT-compiled. It is browser host functionality.
That distinction keeps the statement “JavaScript is compiled before it runs” from becoming too broad.
If bytecode exists, why does JIT still matter?
This was the part I most wanted to understand.
If the engine already has bytecode, why does TurboFan compile again into machine code?
The answer: bytecode is good enough to start quickly, but it is generic.
Take this function:
1 | function add(a, b) { |
When the engine first sees it, it does not know the real types of a and b. They may be numbers:
1 | add(1, 2); |
They may be strings:
1 | add("a", "b"); |
They may also be objects, arrays, or BigInts. JavaScript allows too many possibilities.
So generating the best possible machine code immediately is not realistic. A more practical strategy is: generate bytecode first, run the program, observe the real types at runtime, then compile hot functions with that feedback.
That is the core value of JIT.
TurboFan optimizes hot code under assumptions
Suppose this code runs many times:
1 | function add(a, b) { |
V8 can notice that add is hot and that a and b are consistently numbers.
TurboFan can then generate number-specialized machine code. It no longer needs to ask on every call whether the values are strings, objects, BigInts, or whether valueOf or Symbol.toPrimitive are involved.
Removing those checks is where the speedup comes from.
But the optimization is based on assumptions.
If this later happens:
1 | add("a", "b"); |
the old number assumption is invalid. The engine has to deopt and fall back to a more generic path. Many performance problems are not caused by “no optimization.” They are caused by code that gets optimized and then invalidates the optimization.
Hidden Class and Inline Cache make object access fast
Two other optimizations are worth remembering: Hidden Class and Inline Cache.
For example:
1 | const user = { |
V8 creates an internal structure similar to a Hidden Class for this object shape. A useful first approximation is: it maps property names to slots. name is in slot0; age is in slot1.
If another object is created with the same property order:
1 | const user2 = { |
the two objects can share the same shape. Later, when the engine sees:
1 | user.age; |
it does not need to perform a full property lookup every time. It can get much closer to “read offset1.”
Inline Cache follows the same idea. The first property access is a little more expensive; later, the engine caches how that access site should read the property. As long as the object shape stays stable, the access gets cheaper.
That is why many JavaScript performance tips say: avoid constantly adding and deleting properties, and avoid sending many different object shapes through the same hot path.
The engine is not fragile. Your code is just invalidating assumptions it worked hard to build.
Offset is a useful model, but V8 objects are not simple arrays
While digging into Hidden Class, I had another question: is the offset like an array index, where the engine has continuous memory and reads through pointer plus offset?
That direction is right, but the model needs limits.
V8 objects are more complicated than C arrays. Their properties are not guaranteed to all sit in one continuous memory block. V8 has JSObject, Properties, Elements, fast properties, and dictionary mode. The real implementation is more complex than “object base address plus offset.”
But as a mental model, Hidden Class plus slot or offset is close to C/C++ struct access:
1 | struct User { |
In C++, this:
1 | user->age |
is roughly “object base address plus the offset of age, then read.” Without this kind of optimization, user.age in JavaScript would look more like Map.get("age"): look up the string "age" first, then find the corresponding value.
Hidden Class shortens that path. It maps property names to stable slots, then lets the object read by slot:
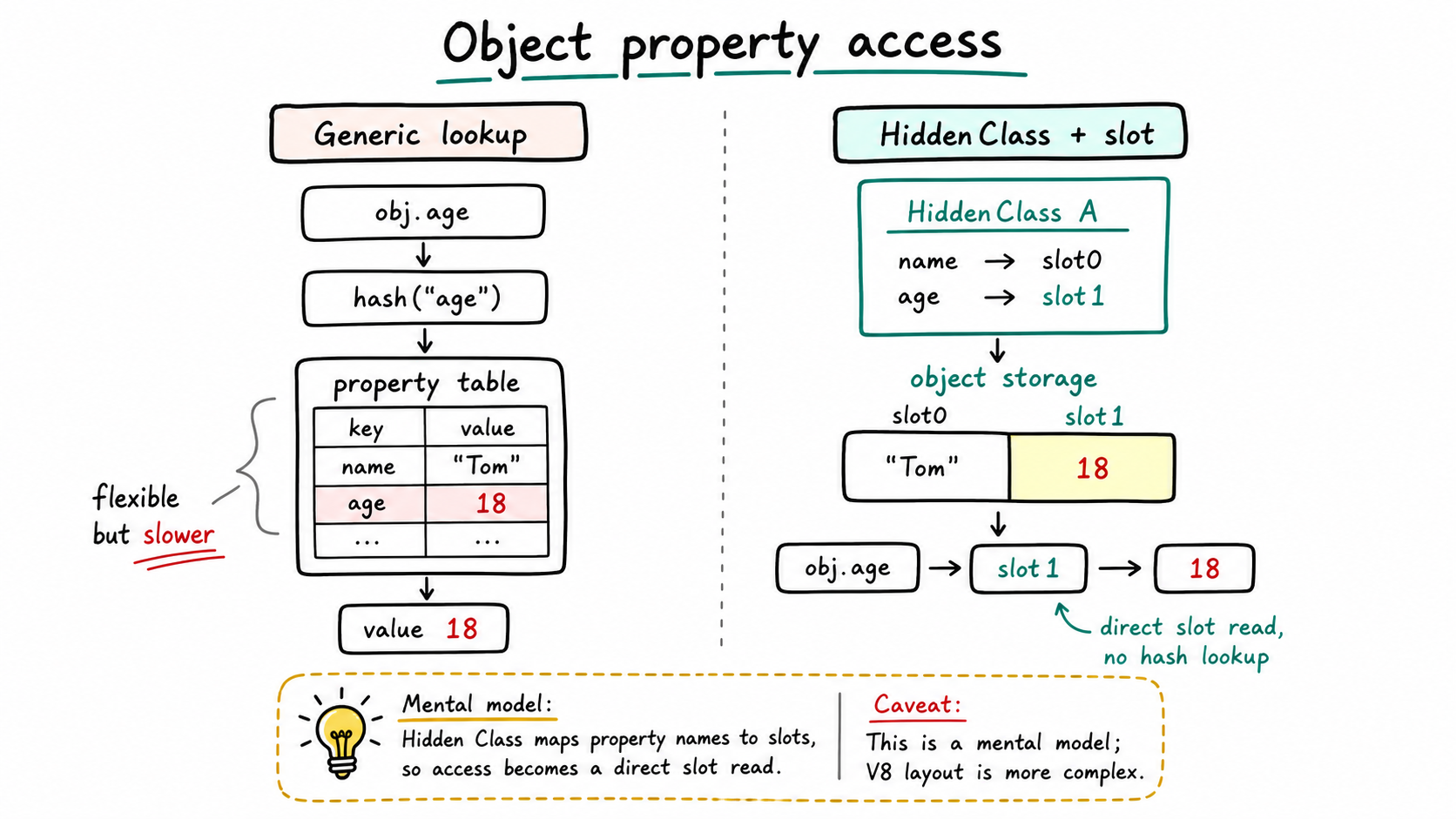
Figure: Generic property lookup is closer to looking up a string in a property table. Hidden Class maps property names to stable slots, so obj.age can move toward a direct slot read. This is a mental model; the real V8 object layout is more complex. generated by gpt-image-2.
So:
1 | user1.age; |
can move from “look up the string” to “know that age is in slot1, then read that slot.” That is why the access can feel similar to array indexing. An array access like arr[1] already uses an index; Hidden Class gives object property access a stable slot first.
The precondition is stable object shape.
1 | const a = { |
These two objects are created in the same order, so they are more likely to share one Hidden Class.
But this object:
1 | const c = { |
has a different property order. V8 may need another Hidden Class: now age may be in slot0, and name may be in slot1. If a hot path keeps seeing A, then B, then many more shapes, Inline Cache and TurboFan both have a harder job.
Dynamic property churn is worse:
1 | obj.a = 1; |
If the object structure keeps changing, V8 may fall from fast properties into dictionary mode. Then property access becomes more like hash-table lookup than stable slot access.
The short version:
You can think of a Hidden Class slot or offset as a fixed position similar to an array index. It lets
obj.agemove from string lookup toward slot lookup. But the underlying layout is not a simple continuous array; the speed comes from Hidden Class, fast properties, and Inline Cache working together.
Inline Cache is tied to a code location, not one object
I also misunderstood Inline Cache at first. When people say the first, second, and third access get faster, does that mean the code contains user.name three times?
No.
It means the same property access location runs repeatedly, and V8 learns what object shapes usually appear at that location.
Take this function:
1 | function printName(user) { |
The key location is:
1 | user.name |
That location is a call site, or more generally a property access site. Inline Cache remembers which Hidden Classes this site has seen before, and which slot contains the property.
First call:
1 | printName({ name: "Tom" }); |
V8 does a full lookup. After the lookup, it records a note next to this access site: if this site sees HiddenClass A again, read slot0 directly.
Second call:
1 | printName({ name: "Jerry" }); |
If the object is still HiddenClass A, V8 does not need to redo the full property-table lookup.
Third call:
1 | printName({ name: "Alice" }); |
If it is still A, the site keeps taking the same cached path.
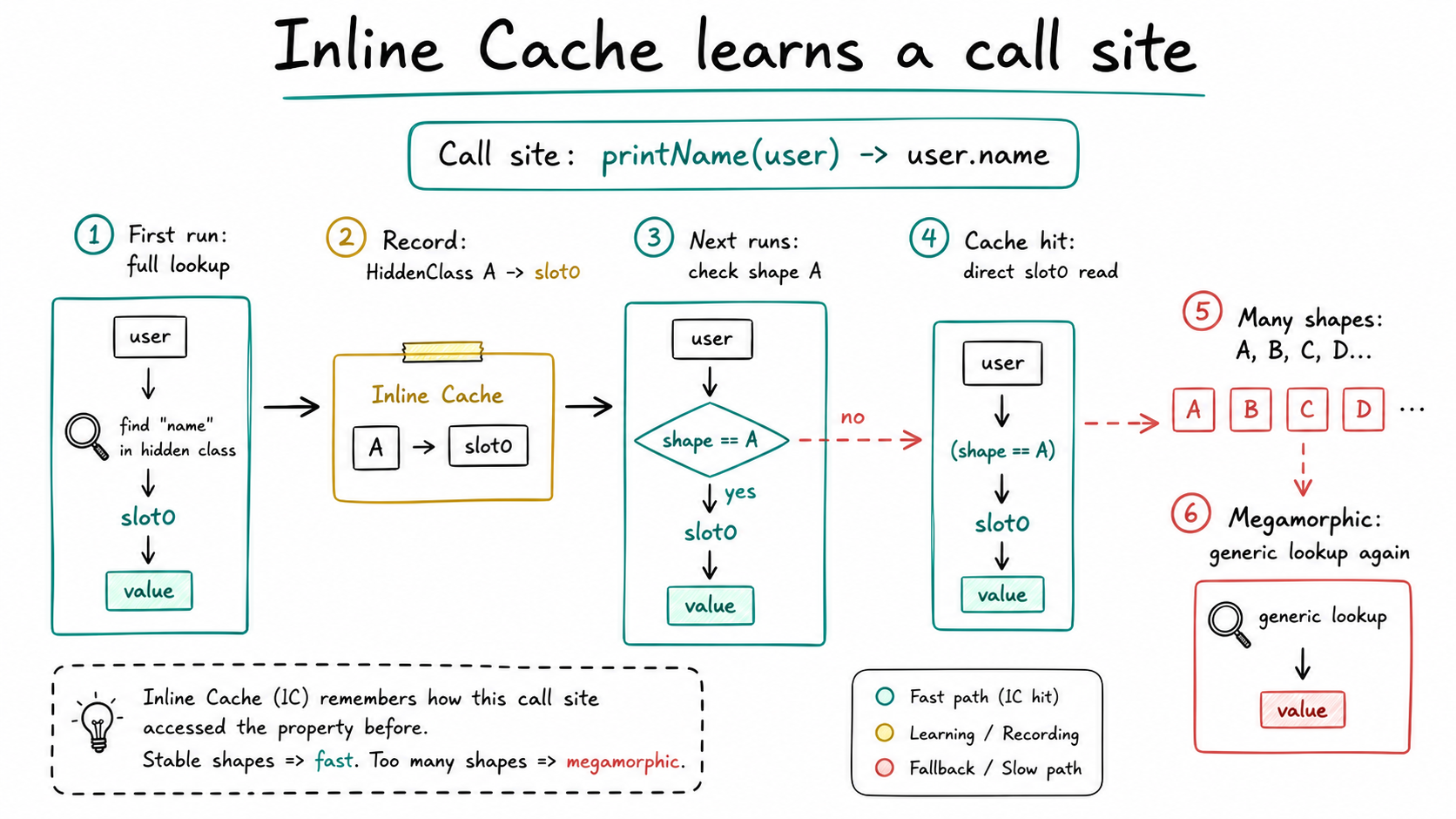
Figure: Inline Cache remembers the Hidden Class and slot seen at one property access site. Stable shapes keep the fast path monomorphic; too many shapes push the site toward megamorphic behavior and a more generic lookup path. generated by gpt-image-2.
At that point, the access site is close to a monomorphic IC. Monomorphic means the site mostly sees one object shape, which is exactly what the optimizer likes.
What if a different shape arrives?
1 | printName({ firstName: "Tom", lastName: "Lee" }); |
This object may be HiddenClass B and may not have name at all. The Inline Cache has to record more cases: how A works, what to do with B, what C means, and so on. This is a polymorphic IC. It can still be optimized, but it is more complex.
If the same access site sees too many shapes, such as A, B, C, D, E, and F, it may become megamorphic. At that point, the engine essentially stops making a narrow guess and falls back to a more generic lookup path.
That is why keeping object shapes stable matters.
For example, React or business code often has:
1 | users.map(user => user.name); |
If every user looks like this:
1 | { id, name, age } |
the access site is more likely to stay monomorphic.
If the list mixes:
1 | { name } |
then the same user.name site keeps seeing different shapes. The IC gets more complicated, and TurboFan has less reason to emit specialized machine code.
A simple analogy is visiting a friend’s house.
The first time, you ask where the bathroom is. The second time, you remember. The third time, you walk there directly.
But if you visit a different friend’s house every day, you cannot rely on the same memory.
That is the intuition behind monomorphic, polymorphic, and megamorphic.
A better question than “is JavaScript interpreted?”
The point of this note is not to memorize the names Ignition and TurboFan.
The better question became:
- What information does the engine not know at startup?
- What does it learn after running the code?
- What assumptions does it make from that feedback?
- Does my code preserve or break those assumptions?
That question is more useful than arguing whether JavaScript is interpreted or compiled.
For interviews, this version is enough:
Modern JavaScript is not simply line-by-line source interpretation. In V8, it usually goes through source code, AST, bytecode, type feedback, and JIT-optimized machine code. Bytecode gives fast startup and generic execution. TurboFan compiles hot code into faster machine code using runtime feedback. When type assumptions fail, the engine deopts back to a more generic path.
For writing better frontend code, I care more about the habit behind it: where does the runtime start generic, what does it learn, and what kind of code makes those assumptions collapse?
I started with a plain question about whether JavaScript is compiled now. The answer was less interesting than the path it opened: parser, bytecode, runtime feedback, optimized code, and deopt. That is usually where the better understanding starts.