今天重学 JavaScript 时,我卡在一个看起来很基础的问题上:我们说 JS “运行”时,它到底已经被编译到了哪一步?
真正有用的不是回答“是”或“不是”,而是把“编译”这两个字拆开。前端工程里说编译,通常是在说 TypeScript、Babel、SWC、esbuild;JS 引擎里说编译,说的是 parser、bytecode、JIT、optimized machine code。同一个词,站的位置不同,意思就变了。
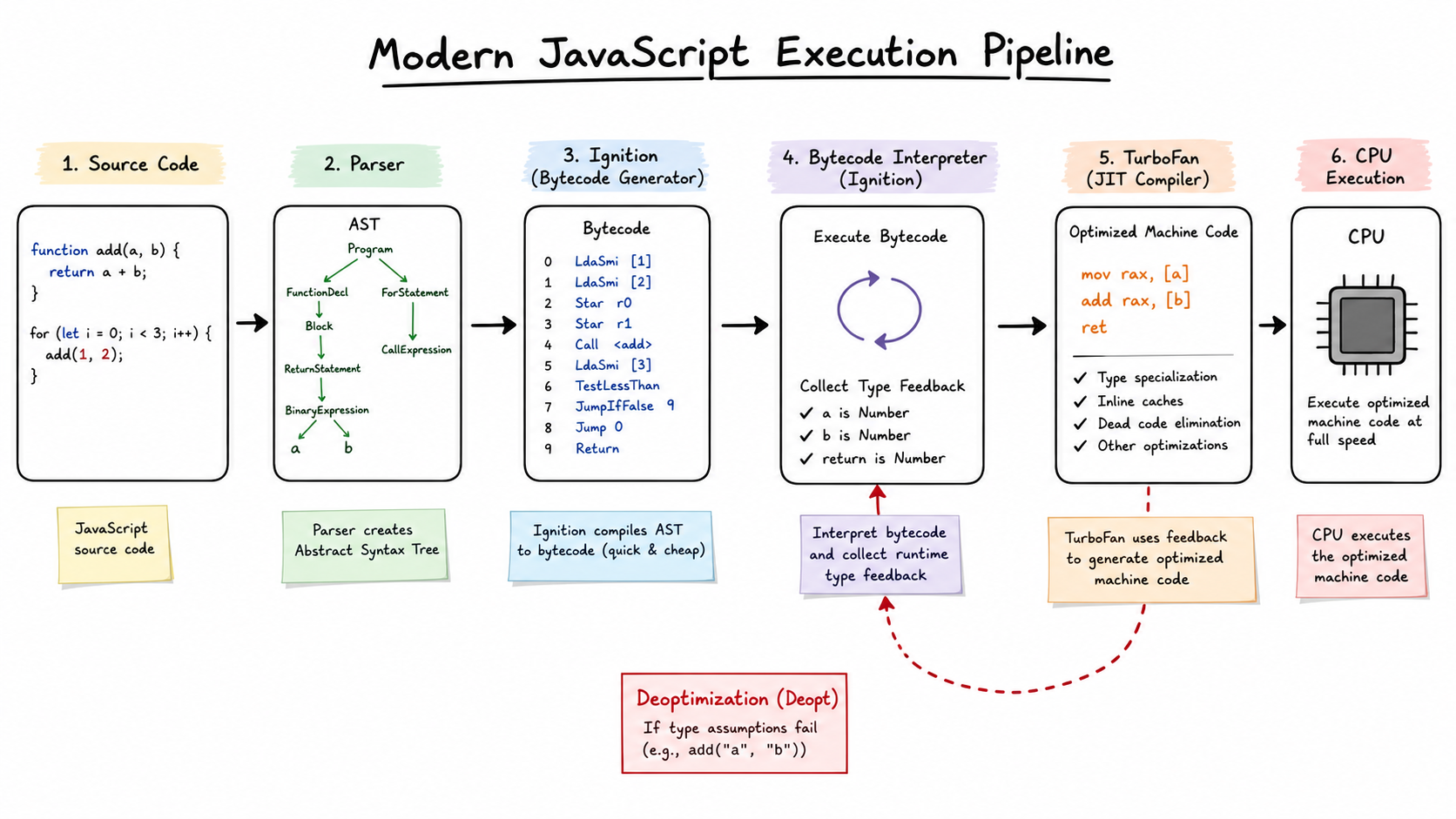
图:现代 JavaScript 在 V8 里的大致执行路径。源码先变成 AST 和 bytecode,运行时收集类型反馈,热点代码再由 TurboFan 编译成优化机器码。generated by gpt-image-2.
前端平时说的编译,浏览器其实不关心
我们最熟的编译发生在 build time。
比如 TypeScript:
1 | const user: User = getUser(); |
最后会变成 JavaScript:
1 | const user = getUser(); |
再比如 optional chaining:
1 | const city = user?.address?.city; |
Babel 可能会把它变成一段兼容性更好的普通 JS。
这一层由 TypeScript、Babel、SWC、esbuild 负责。它解决的是工程问题:类型擦除、语法降级、模块打包、压缩和兼容性。
浏览器不关心你是不是用 TypeScript 写的,也不关心你用了哪个 bundler。浏览器拿到的是最终那份 JS。
浏览器执行 JS 时,还有另一层编译
现代 JS 引擎通常不会“逐行解释源码”。
以 Chrome 的 V8 为例,一个更接近现实的路径是:源码先被 parser 变成 AST,再由 Ignition 生成并执行 bytecode。代码跑起来以后,引擎会收集类型反馈;如果某段代码足够热,TurboFan 再把它编译成优化后的机器码。
这里有两个核心角色:
| 组件 | 做什么 |
|---|---|
| Ignition | V8 的解释器,负责生成并执行 bytecode |
| TurboFan | V8 的优化编译器,把热点代码编译成优化后的机器码 |
所以现代 JavaScript 更准确的说法不是“解释型语言”,而是动态类型语言,加解释器,加 JIT 编译器。
历史上说 JS 是解释型语言没错。早期浏览器确实更接近源码解释执行。
但今天主流浏览器和 Node 都不是这么简单了。Node 用的也是 V8,所以你跑 node server.js,背后也会经过 parse、bytecode、JIT 优化这些阶段。
那浏览器宿主算不算一起被编译?
这里要小心。
JS 引擎编译的是你的 JavaScript 代码。浏览器宿主提供的 DOM、计时器、网络、存储等 Web API,本身大多是浏览器用 C++、Rust、Objective-C 等语言实现的原生能力,再通过 binding 暴露给 JS。
也就是说,你的 JS 代码由 JS 引擎处理;document、fetch、setTimeout 这些宿主能力,则是浏览器原生实现通过 binding 暴露给 JS。
当你写:
1 | document.querySelector("#app"); |
JS 引擎会执行这段 JS 调用逻辑,但真正的 DOM 查询不是把一份 DOM API 的 JS 源码再 JIT 一遍。那是浏览器宿主能力。
这个区分很重要。否则“JS 是编译后运行的”这句话会被说得过头。
有 bytecode 了,为什么还需要 JIT?
这是我这次最想弄清楚的点。
如果已经有 bytecode,为什么还要 TurboFan 再编译成机器码?
答案是:bytecode 足够快地让程序跑起来,但它太通用了。
看这个函数:
1 | function add(a, b) { |
第一次看到这段代码时,引擎不知道 a 和 b 是什么类型。它们可能是 number:
1 | add(1, 2); |
也可能是 string:
1 | add("a", "b"); |
还可能是对象、数组、BigInt。JS 合法的可能性太多。
所以一开始直接生成“最优机器码”并不现实。引擎更实际的策略是:先生成 bytecode 让代码跑起来,再在运行过程中观察真实类型。等某个函数变热以后,再基于这些类型反馈生成专用机器码。
这就是 JIT 的核心价值。
TurboFan 优化的是“假设成立的热代码”
假设这段代码跑了很多次:
1 | function add(a, b) { |
V8 会发现 add 很热,并且观察到 a 和 b 基本都是 number。
于是 TurboFan 可以生成 number 专用的机器码。它不需要每次都问:是不是 string、object、BigInt,有没有 valueOf,有没有 Symbol.toPrimitive。
少掉这些检查,速度就上去了。
但这个优化是建立在假设上的。
如果后面突然来了:
1 | add("a", "b"); |
原来的 number 假设失效,引擎就要 deopt,退回更通用的执行路径。很多性能问题不是“没有优化”,而是“优化了又被你打回去了”。
Hidden Class 和 Inline Cache 是对象访问快的关键
JIT 之外,还有两个特别值得记住的优化:Hidden Class 和 Inline Cache。
比如:
1 | const user = { |
V8 会在内部给这个对象形状创建类似 Hidden Class 的结构。可以先把它理解成一张“属性名到 slot”的映射表:name 在 slot0,age 在 slot1。
如果另一个对象按同样顺序创建:
1 | const user2 = { |
它们可以复用相同的对象形状。之后访问:
1 | user.age; |
引擎不必每次都做完整属性查找,可以更接近“读 offset1”。
Inline Cache 也是类似思路。第一次访问属性时慢一点,后面把“这个位置怎么取”缓存下来。只要对象形状稳定,访问就会越来越便宜。
这也是为什么很多 JS 性能建议都在说:不要随意给对象动态加删属性,不要让同一个 hot path 上对象形状乱跳。
不是因为引擎脆弱,而是因为你在不断破坏它刚刚建立起来的假设。
Offset 可以理解成数组下标,但别把 V8 对象想得太简单
我追到 Hidden Class 的时候,又冒出一个问题:这里说的 offset,是不是就像数组那样,一块连续内存,然后通过 pointer 加偏移量直接访问?
这个理解方向是对的,但要收一点。
V8 的对象不是一个简单的 C 数组,也不保证所有属性都在一块连续内存里。它有 JSObject、Properties、Elements,也有 fast properties 和 dictionary mode。真实实现比“对象起始地址 + offset”复杂。
但作为理解模型,Hidden Class + slot/offset 确实很接近 C/C++ 结构体访问:
1 | struct User { |
C++ 里访问:
1 | user->age |
本质上接近“对象起始地址 + age 的偏移量,然后直接读”。JS 对象如果没有这类优化,访问 user.age 会更像 Map.get("age"):先拿字符串 "age" 去查,再找到对应 value。
Hidden Class 做的事情,就是把这条路径变短。它先把属性名映射到稳定 slot,再让对象按 slot 取值:
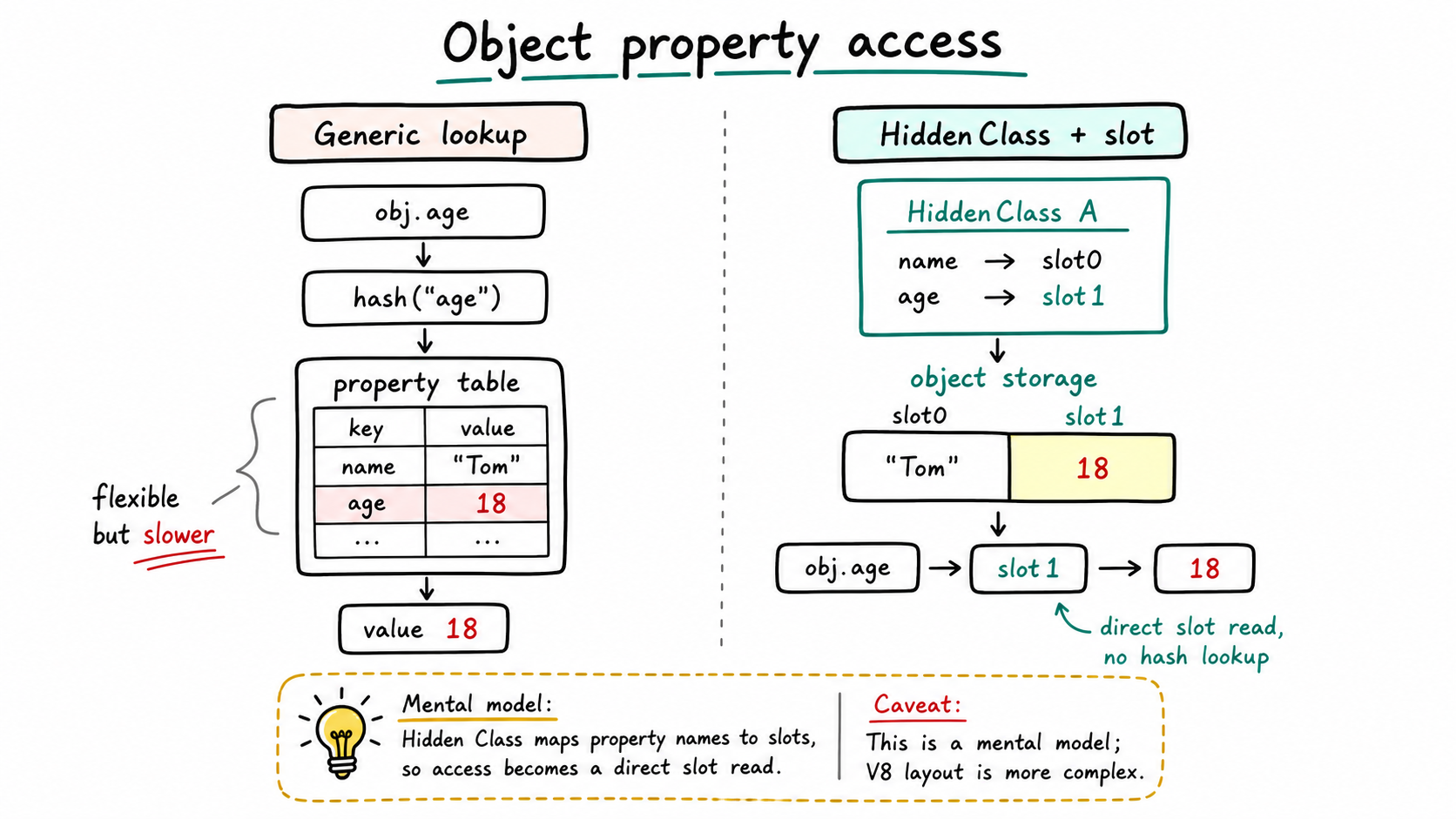
图:普通属性查找更像字符串到属性表的查找;Hidden Class 把属性名映射成稳定 slot,让 obj.age 可以走更接近直接槽位读取的路径。这里是理解模型,真实 V8 对象布局更复杂。generated by gpt-image-2.
所以:
1 | user1.age; |
就可以从“字符串查找”变成“查到 age 在 slot1,然后读取对应槽位”。这就是为什么它接近数组访问。数组访问 arr[1] 本来就是按索引定位;Hidden Class 让对象属性访问也能先把属性名映射成稳定 slot,再按 slot 取值。
但这个前提是对象 shape 稳定。
1 | const a = { |
这两个对象创建顺序一致,比较容易共享同一个 Hidden Class。
如果换成:
1 | const c = { |
属性顺序变了,V8 可能需要另一个 Hidden Class:这次 age 在 slot0,name 在 slot1。如果一个热路径里一会儿来 A,一会儿来 B,一会儿又来更多 shape,Inline Cache 和 TurboFan 都会更难优化。
更糟的是动态增删属性:
1 | obj.a = 1; |
对象结构如果频繁变化,V8 可能从 fast properties 退到 dictionary mode。那就更像哈希表查找,而不是稳定 slot 访问了。
所以一句话概括:
可以把 Hidden Class 的 slot/offset 理解成“类似数组下标的固定偏移量”,它把
obj.age从字符串查找优化成按槽位取值。但底层不是一个简单连续数组,真实速度来自 Hidden Class、Fast Properties 和 Inline Cache 一起配合。
Inline Cache 缓存的是代码位置,不是某个对象
我之前对 Inline Cache 还有一个误解:第一次、第二次、第三次访问更快,是不是指代码里写了三次 user.name?
不是。
这里说的“第一次、第二次、第三次”,是同一个属性访问位置反复执行时,V8 逐渐学会这个位置通常会看到什么对象 shape。
看这个函数:
1 | function printName(user) { |
关键位置是:
1 | user.name |
这个位置叫 call site,或者更宽泛地说,是一个属性访问点。Inline Cache 记的是这个位置过去见过什么 Hidden Class,以及对应属性在哪个 slot。
第一次执行:
1 | printName({ name: "Tom" }); |
V8 需要做完整查找。查完之后,它会在这个访问点旁边记一笔:如果下次这里又看到 HiddenClass A,可以直接读 slot0。
第二次执行:
1 | printName({ name: "Jerry" }); |
如果这个对象还是 HiddenClass A,V8 就不需要重新查属性表。
第三次执行:
1 | printName({ name: "Alice" }); |
还是 A,就继续走同一条缓存路径。
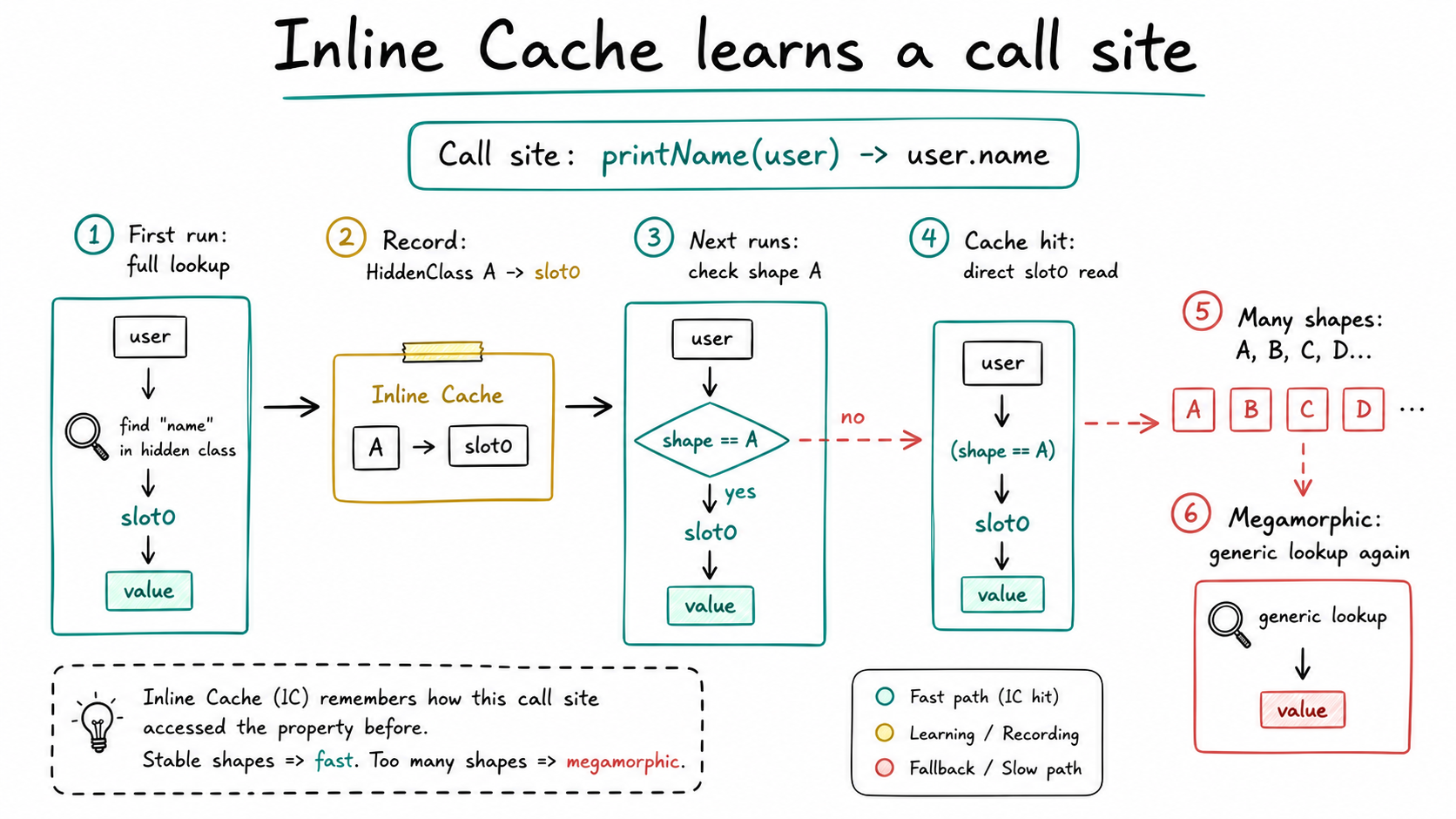
图:Inline Cache 缓存的是同一个属性访问点见过的 Hidden Class 和 slot。shape 稳定时,后续调用可以命中 fast path;shape 太多时,会走向 megamorphic,退回更通用的查找路径。generated by gpt-image-2.
这时这个访问点接近 monomorphic IC,也就是单态缓存。单态是优化器最喜欢的状态,因为它意味着“这个地方基本只来一种对象形状”。
如果来了不同 shape 呢?
1 | printName({ firstName: "Tom", lastName: "Lee" }); |
这个对象可能是 HiddenClass B,而且根本没有 name。Inline Cache 就要记录更多情况:A 怎么读、B 怎么处理、C 又是什么形状。这叫 polymorphic IC,多态缓存。还能优化,但已经比单态复杂。
如果一个访问点见过太多 shape,比如 A、B、C、D、E、F 一路堆上去,它就可能变成 megamorphic IC。这个时候 V8 基本会说:这个地方太乱了,别猜了,走更通用的查找逻辑吧。
这也是为什么保持对象 shape 稳定有意义。
例如 React 或业务列表里经常写:
1 | users.map(user => user.name); |
如果所有 user 都长得像:
1 | { id, name, age } |
这个访问点更容易保持 monomorphic。
如果列表里混着:
1 | { name } |
那同一个 user.name 会看到越来越多 shape。IC 越来越复杂,TurboFan 也更难放心生成专用机器码。
我觉得最形象的类比是找朋友家的厕所。
第一次去,要问在哪。第二次去,记住了。第三次去,直接走过去。
但如果你每天去的都是不同朋友家,就永远别想闭着眼找到。
这就是 monomorphic、polymorphic、megamorphic 背后的直觉。
重新看“JS 是解释型语言”
这次重学的重点,不是背下 Ignition 和 TurboFan 的名字。
真正有价值的是换了一个问法:
- 引擎在什么时候不知道信息?
- 它运行一段时间后知道了什么?
- 它基于这些信息做了什么假设?
- 我的代码会不会破坏这个假设?
这比简单争“JS 是解释型语言”还是“编译型语言”更有用。
如果只为了面试,可以记这个版本:
现代 JavaScript 不是传统意义上的逐行解释执行。在 V8 里,它通常会经历源码、AST、Bytecode、类型反馈和 JIT 优化机器码。Bytecode 负责快速启动和通用执行;TurboFan 负责把热点代码按运行时反馈编译成更快的机器码;当类型假设失败时,引擎会 deopt 回到更通用的路径。
如果是为了写更好的前端代码,我更在意背后的习惯:运行时什么时候只能走通用路径?它跑了一会儿之后学到了什么?我的代码会不会让这些假设失效?
我一开始只是想问:JS 现在算不算编译后运行?最后挖到的是 parser、bytecode、类型反馈、优化机器码和 deopt。这个过程比标签本身更有用。