词汇表
- 计算过程(computational process,巫师脑中的精灵):一种思想,看不见也摸不到,但能解决问题并驱动现实世界。
- 程序(program,巫师的咒语):通过编程语言规定计算过程,操纵另一种抽象事物——数据。
- 程序员(programmer,巫师的学徒):构思想法并施展咒语的人。
- 数据(data):
- JavaScript:我们的咒语格式,它从 Scheme 继承了核心特性:一等函数和动态类型。
问题
- 如何让你的咒语精确完成你想要的事情?
- 如何提前预见系统的运行方式(测试?)
- 如何确保在出现意外问题时不会导致灾难性后果(容错?)
- 当问题出现时如何调试(监控?)
笔记
- 让你的咒语精确完成你想要的事情
- 良好设计的程序以模块化方式构建,使各部分可以独立构建、替换和调试(人类的局限所在:化繁为简!复杂的想法由多个简单想法组成,所以只需将其分解。)
1.1 编程的基本要素
词汇表
- 原始表达式(primitive expressions):语言所涉及的最简单实体。
- 组合手段(means of combination):由更简单的元素构建复合元素的方式。
- 抽象手段(means of abstraction):将复合元素命名并作为单元进行操作的方式。
- 数据(data):我们想要操作的”材料”。
- 函数(function):描述操作数据规则的东西。
问题
笔记
- 强大的语言作为框架来组织我们对过程的想法。(关注语言提供了哪些组合简单想法的手段。面向对象编程?不仅仅是语言,像 React 这样的框架也提供了精心设计的抽象(虚拟 DOM),以及一种便于组织模块化前端组件的方式。)
1.1.1 表达式
词汇表
- 表达式(expression):由一个_表达式_后跟一个分号组成。(在我看来,一行基本上就是一个表达式。)
- 原始表达式:
- 数字
- 组合表达式:
- 由其他表达式组合而成的表达式(运算符组合)
- 原始表达式:
问题
笔记

1.1.2 命名与环境
词汇表
- 命名(naming):提供名称-值的存储,是最简单的抽象手段,提供了一种复用复杂值(组合表达式)的简便方式。
- 环境(environment):命名的代价(创建一个值并通过引用其名称来复用它)是我们必须维护一种内存来保存键值对,这就是环境。
问题
笔记
1.1.3 求值运算符组合
词汇表
问题
笔记
- 我们不会一直对组合表达式求值,有时只对原始表达式(如数据或名称)求值。
- 求值运算符组合本质上是一个递归过程,如下所示:

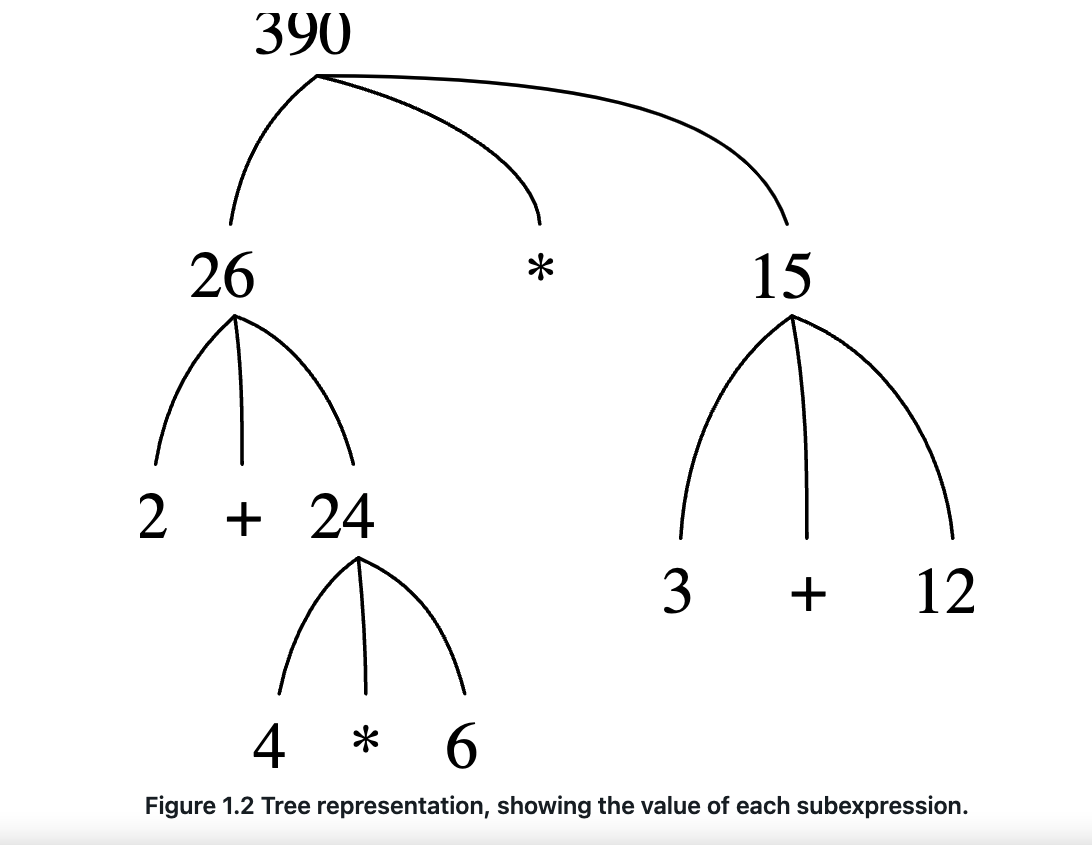
1.1.4 复合函数
词汇表
- 复合函数(compound functions):本质上是一种组合手段(将多个表达式组合在一起)和抽象手段(作为一个单元,通常代表一种操作)——与命名数据相比,它抽象的是操作。
问题
笔记

1.1.5 函数应用的代换模型
词汇表
- 代换模型(substitution model):对复合函数应用于参数求值,即将函数返回表达式中的每个形参替换为对应的实参。
- 正则序求值(normal-order evaluation):完全展开后再归约。JavaScript 出于效率考虑使用代换模型,但正则序求值可以是一种非常有价值的工具。
问题
笔记
1.1.6 条件表达式与谓词
词汇表
- 谓词(predicate):返回 true 或 false 的表达式。
- expression__1 && expression__2:expression__1 ? expression__2 : false
- expression__1 || expression__2:expression__1 ? true : expression__2
- !expression:expression__1 ? false : true
问题
笔记
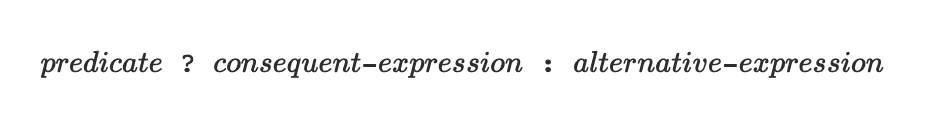
- 注意,
&&和||是语法形式,而非运算符;它们右边的表达式并不总是会被求值。
1.1.7 示例:牛顿法求平方根
词汇表
问题
笔记
将一个大程序拆分为若干小块,并分别构建。
通过函数调用,无需任何循环语法就可以构建迭代结构。
 参见应用序求值
参见应用序求值
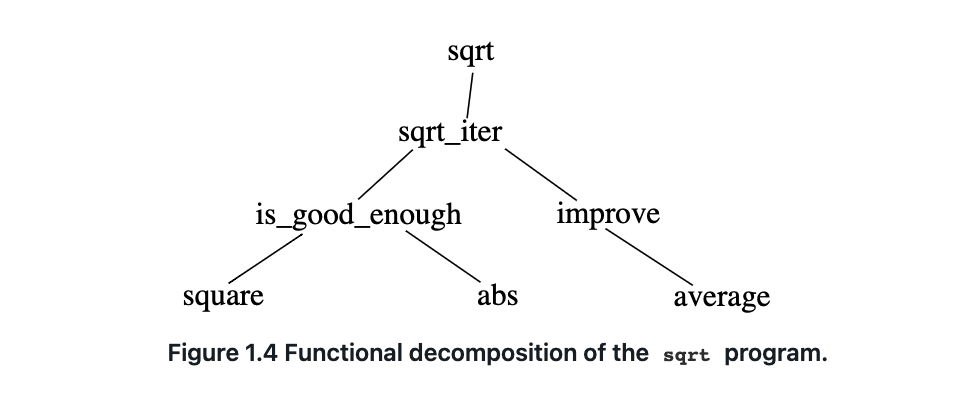
关键在于每个函数都要完成一项可识别的任务,并且能够作为模块在定义其他函数时加以使用。(如何完成最大的任务?将其分解成小块;如何完成这些小块?…)
1.1.8 作为黑盒抽象的函数
词汇表
- 黑盒(black box):不关心如何做,只关心是什么。所以一个函数应该能够隐藏细节(尽可能隐藏不必要的细节)。
- 局部名称(local name):函数参数名无关紧要,由函数作者使用,绝不能影响调用者。
- 块结构(block structure):作为模块,我们在块结构
{}内声明所有变量和函数,使边界更加清晰(_词法作用域_,封装)。
问题
笔记
- 阅读源代码时,先将其视为黑盒,只关心它做了什么(函数名),这能省去很多麻烦。
- 我们将广泛使用块结构来帮助我们将大型程序分解为可处理的小块。
1.2 函数与它们生成的过程
词汇表
问题
- 如何抽象函数?(如何拆分任务?)
- 如何预测一个行动的后果?
笔记
- 可视化后果。
- 函数是计算过程_局部演化_的模式。它规定了过程的每个阶段如何建立在前一个阶段之上。
1.2.1 线性递归与迭代
词汇表
线性递归(shape):一条延迟操作的链,解释器跟踪稍后要执行的操作。链的长度为 n。时间复杂度 O(n),空间复杂度 O(n)。
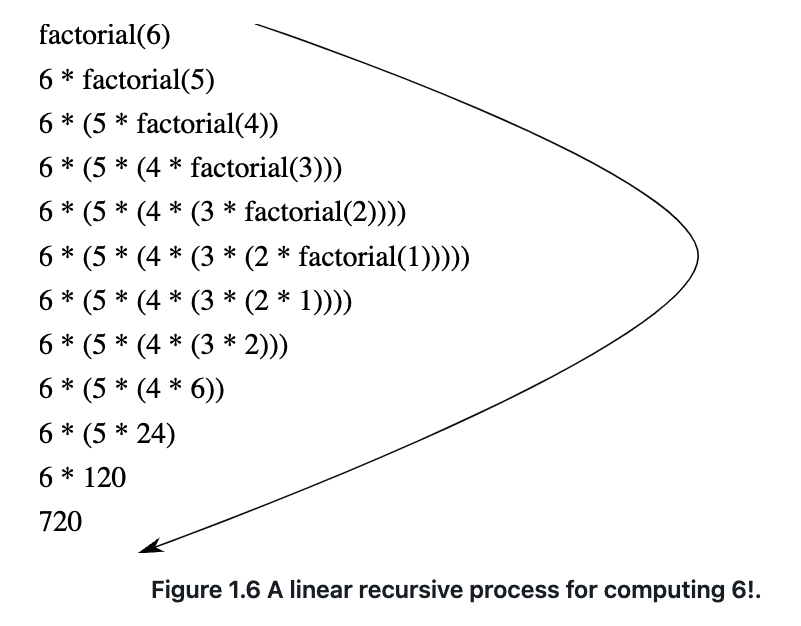
线性迭代(linear iterative):无需增长和收缩。状态可以由固定数量的_状态变量_概括,以及描述状态如何从一个状态更新到另一个状态的固定规则,以及一个(可选的)指定终止条件的结束测试。时间复杂度 O(n),空间复杂度 O(1)。
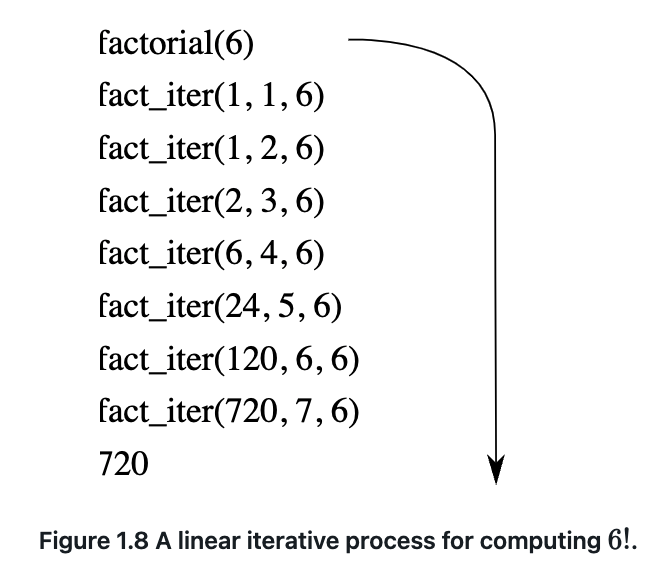
区别:迭代过程不需要解释器存储某些”隐藏”状态,所有描述都由状态变量提供。而递归过程借助解释器存储状态,链越长,解释器需要维护的状态就越多。
递归函数(recursive function):指在语法上引用自身的函数,与递归过程无关。递归函数也可以是迭代过程。
递归过程(recursive process):函数的一种演化方式,将状态留给解释器,并调用下一个函数。
尾递归(tail-recursive):常见语言即使在迭代过程的递归函数中也会消耗空间。但 JavaScript 具有尾递归优化,消耗常数空间。借助尾递归实现,迭代可以使用普通的函数调用机制来表达,特殊的迭代构造只作为语法糖存在。
问题
笔记
- 为什么递归会展开?我认为这是因为我们从上往下看问题,所以需要一直存储”如何解决最顶层问题”,而如果你从下往上看问题,则只需更新状态,无需关心底层问题的解法(我们的目标始终是最顶层的问题)。
1.2.2 树形递归
词汇表
问题
笔记
函数调用自身两次会形成一棵二叉树。我们可以用树状图来分析时间复杂度。(本质上是关于如何在其他函数之上演化函数。)
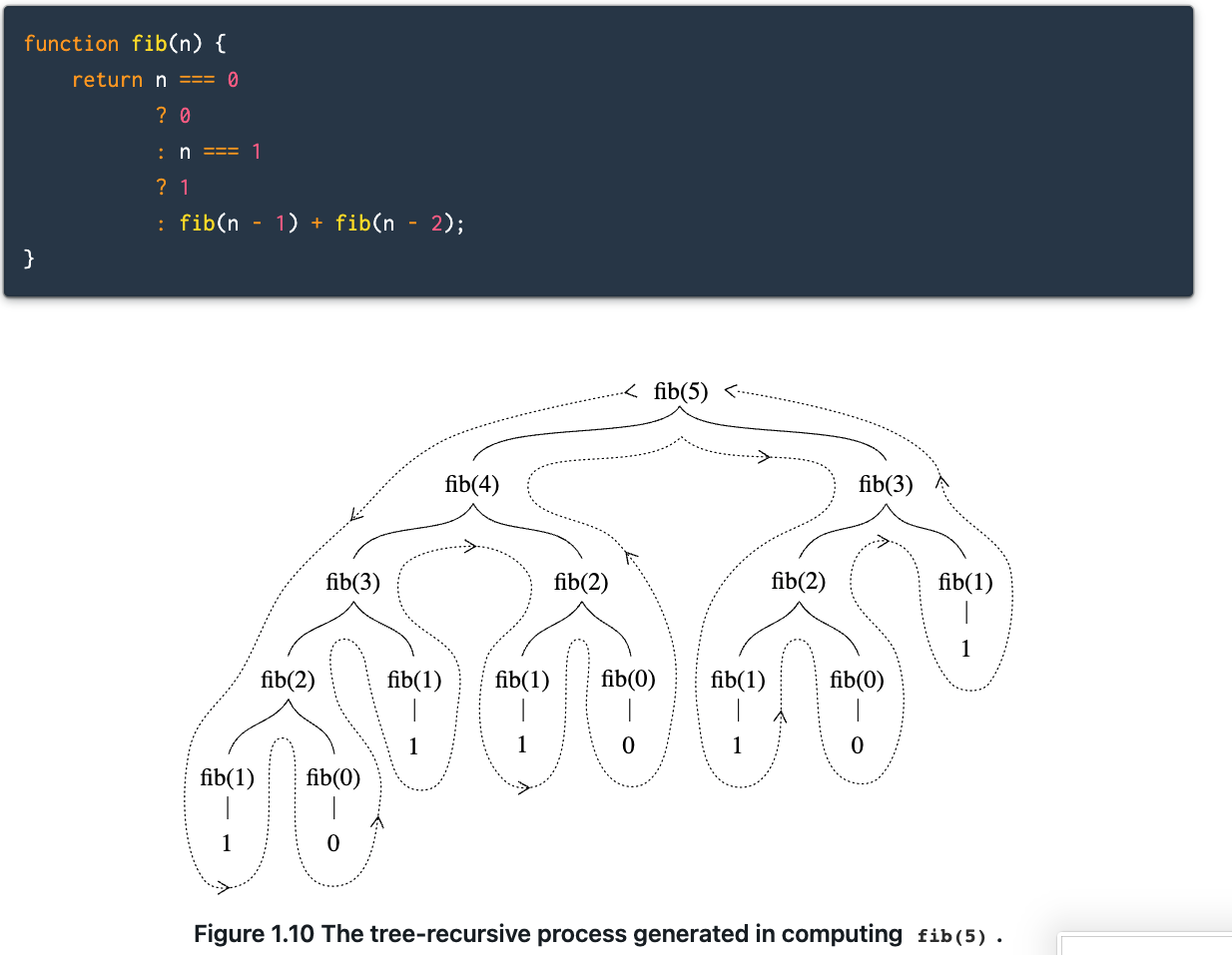
树形递归对于树状结构数据或图来说非常有用,且比迭代过程更直观。
改为迭代过程:从下往上思考,f(n) = f(n-1) + f(n-2),所以 f(n) + f(n-1) = f(n+1),我们需要两个状态来存储 n 和 n-1,以及一个限制条件计数。
1 | function fib(n){ |
- 找零钱
我们能用多少种不同的方式找开 1 美元(100 美分),已知有半美元、25 美分、10 美分、5 美分和 1 美分(即 50 美分、25 美分、10 美分、5 美分和 1 美分)?
1 | // problem: given 100 or n, count the ways of splitting it in |
- 练习 1.11
1 | // recursive |
- 练习 1.12
1 | // consider p[i][j] |
1.2.3 增长阶
词汇表
- 增长阶(order of growth):描述过程所使用计算机资源的方式,通常指时间和存储空间。
- n:我们将问题规模描述为 n。
- R(n):规模为 n 的问题所使用的资源量。
问题
笔记
1.2.4 求幂
词汇表
问题
笔记
- 练习 1.16
1 | // fast expt: given b and n, calculate b^n |
1.2.5 最大公约数
词汇表
- GCD(最大公约数)
问题
笔记
- 辗转相除法:个人理解,把 a 和 b 看成 m 份 x 和 n 份 x,其中 x 为 GCD(a, b),因为是最大公约数所以显然可以把 a 和 b 分成 m/n 份。a % b = r,= m * x - r * n * x = g * x,他们的最大公约数仍然是 x。
1 | // GCD(a, b) = GCD(a, r) r = a % b |
- 观察正则序求值和应用序求值所生成的不同过程。
1.2.6 示例:素性检验
词汇表
- 因子测试(divisors test):测试是否存在因子 1 < d < n。注意:n/d * d = n,所以 n/d 和 d 中必有一个小于 sqrt(n),另一个大于。如果找不到小于 sqrt(n) 的因子,那么显然也不存在大于 sqrt(n) 的因子。
- 费马小定理(Fermat’s Little Theorem):如果 n 是素数,a 是任意小于 n 的正整数,则 a 的 n 次方与 a 对 n 同余。
- 概率算法(probabilistic algorithms):可以证明误差概率可以任意缩小的一类测试算法。
问题
笔记
- 因子测试
1 | function is_prime(n) { |
- 费马测试
1 | // if n is prime, then a^n mod n = a mod n, if 0 < a < n. O(time*logn) |
1 | // for testing the time cost of the function, we make a high order function |
1.3 用高阶函数构建抽象
词汇表
- 函数(回顾):函数是对某些操作组合的抽象,以便更好地复用。
- 高阶函数(high-order function):我们需要一种方式将操作抽象为函数,这就是高阶函数——将函数作为参数传入,并将函数作为返回值。
问题
笔记
- 同一种编程模式往往会在许多不同的函数中使用。
1.3.1 函数作为参数
词汇表
问题
笔记
- 函数作为参数:找出多个函数的公共模式,将其提取为高阶函数。
- 求和:
考虑以下三个函数:
1 | function sum_integers(a, b) { |
我们可以将大部分相同部分提取为一个新函数,将不同之处留作具体函数 term 和 next:

这是数学中的求和:
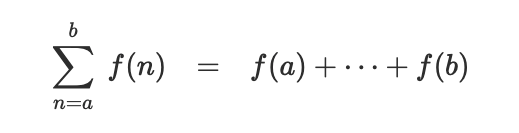
- 练习 1.29
1 | function summate(a, b, f, next) { |
- 练习 1.31
1 | function product(a, b, f, next) { |
- 练习 1.32
1 | // use same thought to extract common partern of summate and product function |
1.3.2 使用 Lambda 表达式构建函数
词汇表
- Lambda 表达式(Lambda Expressions):形如
x => x + 4的无名称形式。便于作为参数传递给函数。当有一些小表达式不需要声明为函数时使用,特别是那些永远不会被复用的函数。 - 条件语句(if else):将表达式转换为块,可以在块内写更多信息。
问题
笔记
1.3.3 函数作为通用方法
词汇表
问题
笔记
- 用区间折半法求方程的根
给定 f(x),求 f(x) = 0 的根。同时给定边界 a、b,根在 [a, b] 之间。
解法:
- 朴素方法:从 a 枚举到 b,判断 f(x) 是否等于 0 或接近 0。由于 a 和 b 是连续的,时间复杂度取决于精度。
- 折半法:当且仅当根在 a、b 之间时,f(a) * f(b) < 0。取 a、b 的中点 x,验证 f(x) * f(a) 或 f(x) * f(b) 是否小于 0,然后将 x 设为新的 a 或 b,缩小范围。当范围小于阈值 T 时结束。时间复杂度 O(log((b-a)/T))。可以将 T 视为最小单位,当 T 等于 1 时为 O(log(b-a))。
1 | function find_root(f, r, a, b) { |
1.3.4 函数作为返回值
词汇表
问题
笔记
- 函数作为参数:抽象组合/操作函数的手段。
- 函数作为返回值:基于原始函数创建新函数,通常是为函数包装额外逻辑,或将多个函数组合成一个。
1 | // example 1: make a damp to a function for instance x -> x * x |
这是一种表达能力的增强:没有函数作为参数,我们无法表达对其他函数进行操作的抽象;没有函数作为返回值,我们无法表达对函数进行包装/升级的抽象。
- 导数(derivative):Dg(x) = (g(x+dx) - g(x)) / dx,dx 是一个很小的数,我们计算 g(x) 在 x+dx 和 x 之间的差值,然后除以 dx。
1 | // deriv is a new function base on g(x), so we can use fn as return value to |
我们在 1.3 节开始时观察到,复合函数是一种关键的抽象机制,因为它们允许我们将通用计算方法表达为编程语言中的显式元素。现在我们已经看到了高阶函数如何让我们操纵这些通用方法,以创建更进一步的抽象。
我们应该始终保持警觉,寻找在程序中识别底层抽象的机会,并创建更强大的抽象——但这并不意味着我们应该总是以最抽象的方式编写程序。专家程序员知道如何选择适合其任务的抽象层次。但重要的是要能够用这些抽象进行思考,以便在新的情境中能够随时应用它们。
一等元素(first-class elements):编程语言对其操纵施加最少限制的元素。
- 可以用名称引用。
- 可以作为参数传递给函数。
- 可以作为函数的结果返回。
- 可以包含在数据结构中。
JavaScript 中函数作为一等元素:表达能力更强,但高效实现是一个挑战。
练习 1.40
1 | // given param, generate a function |
- 练习 1.41
1 | function double(f) { |
- 练习 1.42
1 | // abstraction of compose |
- 练习 1.43
1 | // given a function and n times, modify the function to repeat itself n times |
- 练习 1.44
1 | // smoothing function, times |
- 练习 1.46
迭代改进:为了计算结果,我们先从一个初始猜测值开始,然后判断是否足够好,若不是,则重复该过程。
1 | function iterative_improve(improve, is_good_enough) { |
- 目前我们拥有的抽象:
- 命名:表达的抽象。
- 函数:操作的抽象。
- 基本函数:对数据操作的抽象。
- 高阶函数:
- 函数作为参数:对函数操作(组合函数)(思想)的抽象。
- 函数作为返回值:对函数进行修改/升级(思想)的抽象。
这一切都是关于提升你的表达能力。