摘要
本文介绍如何运用 OpenAI 的多种技术,打造一个能够回答用户问题并与其进行交互的智能 GPT 客服聊天机器人。
我们主要使用的技术包括:
- Embeddings(嵌入):该技术将我们的知识库(如 FAQ 和产品设计等文档)转化为一组向量,从而可以通过比较文本向量来轻松检索与问题相关的上下文。了解更多关于嵌入的信息,请参阅 OpenAI API。
- “Few-shot” 提示(少样本提示):通过给 GPT 提供少量示例,让它轻松学会如何解决新任务。这被称为”few-shot”提示。了解更多关于上下文学习的信息,请参阅 Wikipedia。
- 向量数据库(向量相似性搜索引擎):这是处理嵌入后存储向量的地方。它提供了一个便捷且高效的搜索 API,用于查找最接近的前 k 个向量。
- 改写(Paraphrasing):为了使聊天机器人具备上下文感知能力,我们需要在提问之前对用户的问题进行改写,以提供上下文信息。
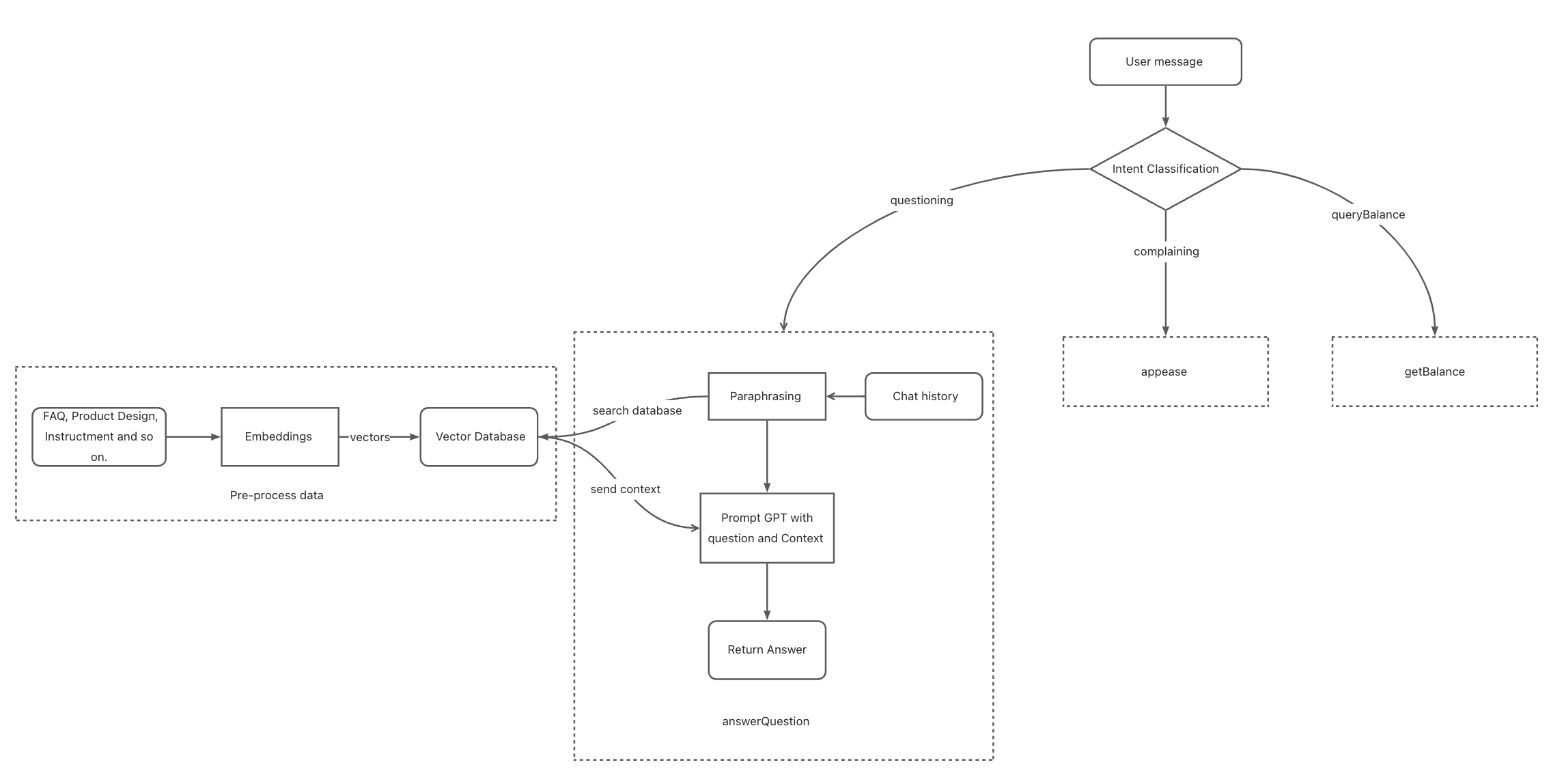
- 意图分类(Intent Classification):为了让聊天机器人能够处理不同类型的任务,我们需要首先对查询类型进行分类,以决定使用哪条指令。意图分类是一种基于 GPT 对查询意图进行分类的技术。
第一阶段:基于文档回答客户问题
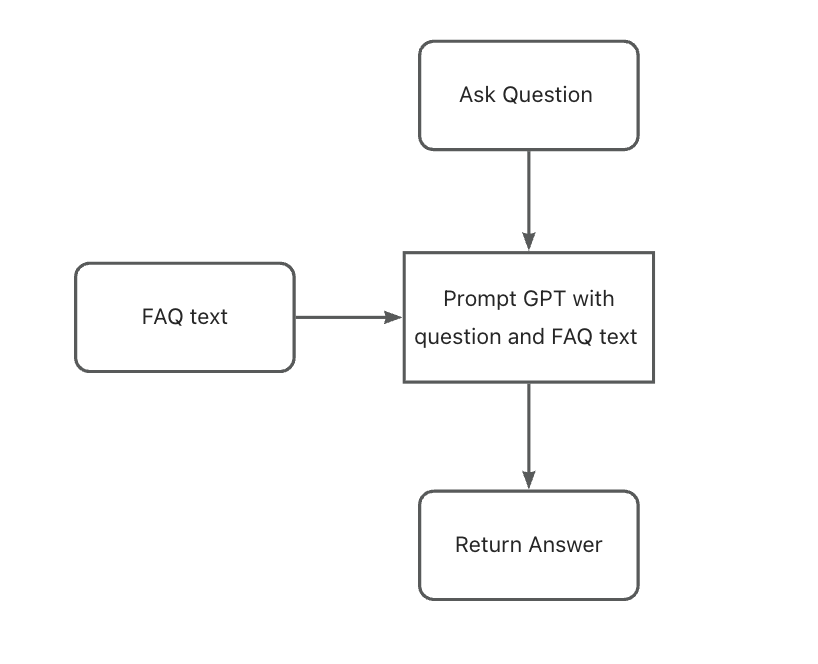
使用 GPT-3.5 结合少量 FAQ 文本回答问题
让 GPT 基于短文本回答问题非常简单。我们将创建一个函数,当用户提出问题时,以参考文本和用户问题调用 OpenAI GPT-3.5 模型。
使用 Embeddings 和向量数据库扩展问答能力
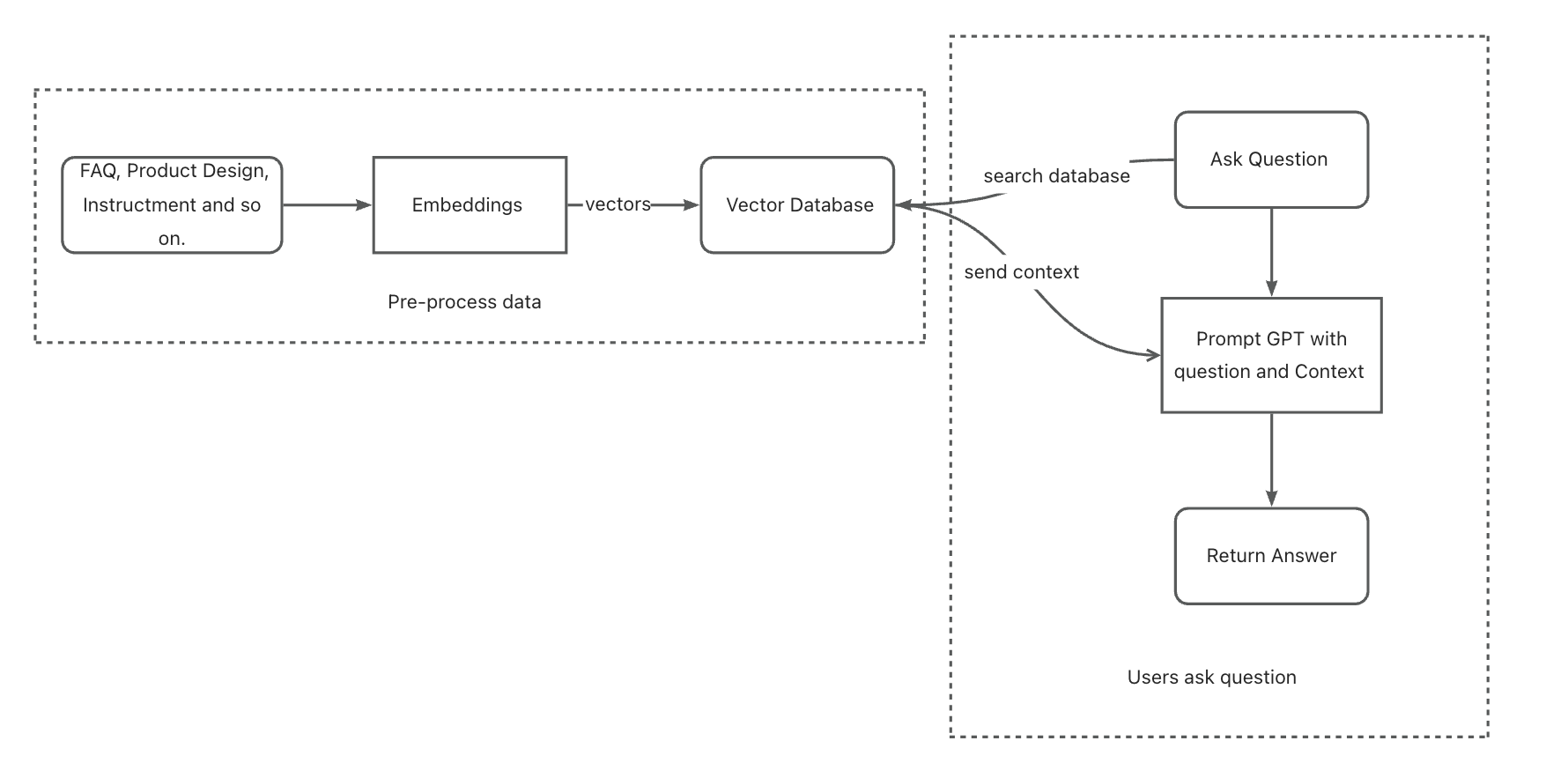
我们的聊天机器人需要在不消耗过多 token 的情况下记忆更多文本。然而,GPT 在记忆大量文本方面存在局限性。为了解决这个问题,我们将在系统中引入 Embeddings 和向量数据库。
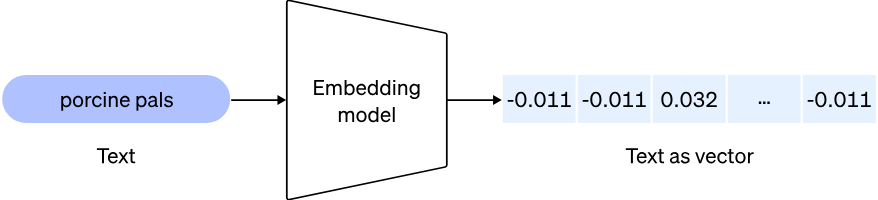
首先,我们将使用 openai 的嵌入模型 "text-embedding-ada-002" 处理大型文档,作为聊天机器人的数据。这会将文本转化为一组向量。
之后,我们将这些向量存储在名为 qdrant 的向量数据库中。这样我们就可以在之后查询与用户问题最相关的文本片段。
当用户提出问题时,我们的聊天机器人会首先在向量数据库中查询上下文信息,然后将该上下文与问题结合起来提示 GPT。
第二阶段:支持上下文感知回答
无论知识库有多大,我们的聊天机器人都能回答用户的各种问题。然而,仍然存在一个关键问题:聊天机器人无法记住用户与其之间的聊天历史。例如,用户问”A 是什么?”,我们的聊天机器人回答”A 是 xxxx…”,然后用户再问”使用它需要连接互联网吗?”。我们的聊天机器人很可能无法回答,因为它不知道”它”指的是什么。
为了解决这个问题,我们引入了一种叫做改写的技术,让我们在向聊天机器人提问之前重新构造问题。在改写过程中,我们根据聊天历史替换用户问题中的某些词语(如”它”)(改写的作用不止于此,它还能优化问题)。我们使用 GPT 来完成这项任务。
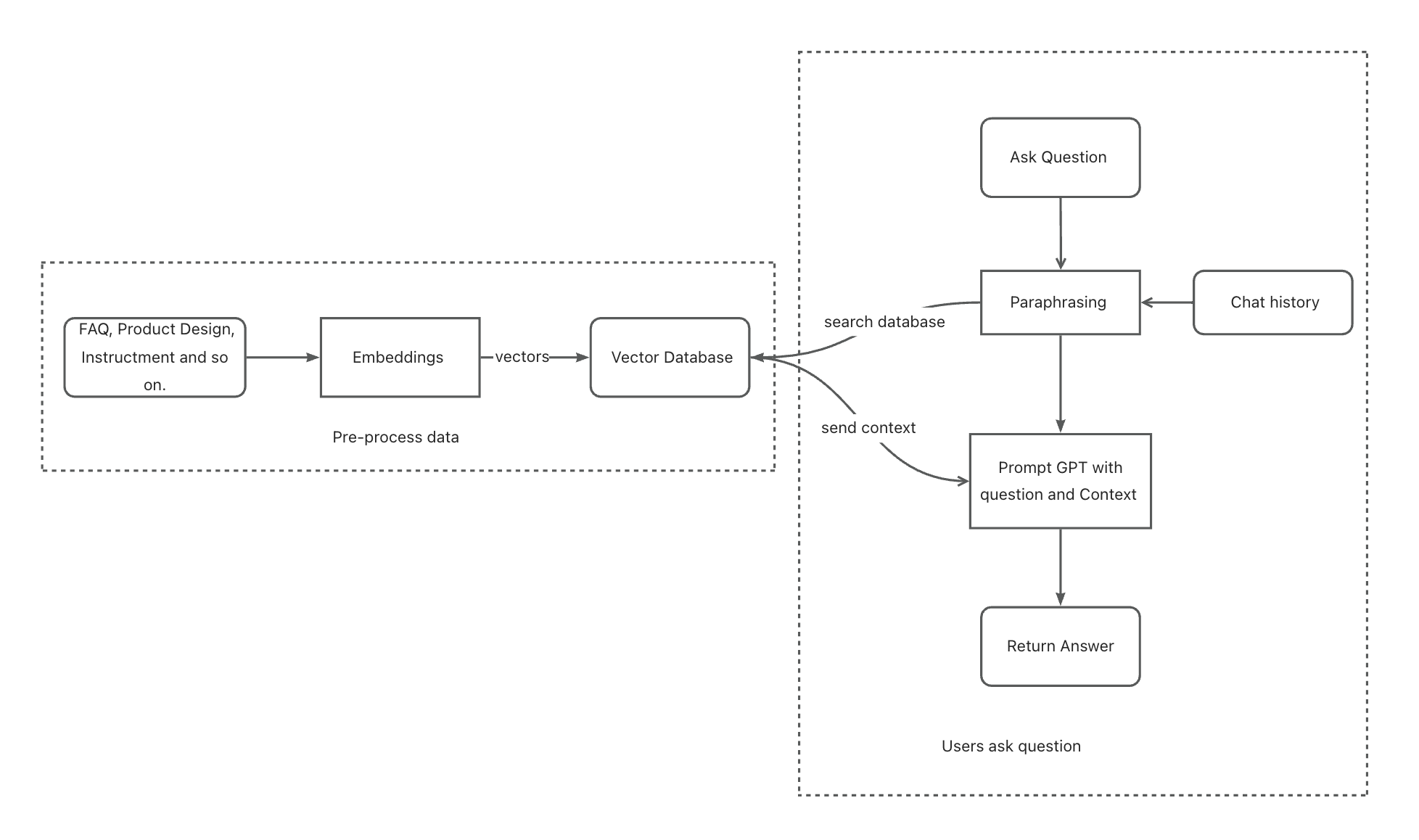
改写过程中的提示工程优化
我们使用 “Few-shot” 提示来帮助 GPT 更好地理解如何基于上下文改写问题。
在让 GPT 改写问题之前,我们将提供一个练习轮。提示类似于以下示例,可根据需要进行调整:
1 | [ |
第三阶段:支持安抚客户与调用外部 API
我们希望聊天机器人能够处理更多类型的任务,而不仅仅是回答问题。例如,我们希望它能安抚正在投诉的客户,或者在用户询问余额时调用 API 查询用户余额。
为了提供这种能力,我们在处理任务之前增加了一层用于分析用户意图的处理。这一步骤称为意图分类。
我们如何根据用户的消息了解其真实意图?GPT 非常擅长这项任务。有关更多信息,请参阅 Intent Classification - OpenAI。
模块化:我们现在可以将之前的流程作为一个名为 answerQuestion 的模块。假设我们还有两个模块,分别是 appease 和 getBalance,我们可以创建三类用户意图:questioning(提问)、complaining(投诉)和 queryingBalance(查询余额)(仅作示例)。
当用户发送消息时,我们的提示如下:
系统:你将收到客服查询。将每个查询分类到不同的类别。以 JSON 格式输出,键为:category。
类别:questioning、complaining、queryingBalance。
用户:你的产品简直是垃圾!
获取包含类别的 JSON 后,我们可以开始调用相应的模块来处理用户消息。这样我们就不会将不同类型的任务混在一起,使我们的系统更具可扩展性。
总结
在本文中,我们学习了如何从简单到复杂,使用最新 GPT 技术打造一个客服聊天机器人。我们介绍了 embeddings(嵌入)、**”few-shot” 提示、向量数据库、改写和意图分类等技术。本文还详细介绍了扩展聊天机器人的过程,以及如何支持上下文感知回答、安抚客户和调用外部 API。我们的方法以模块化等软件工程原则为指导,使聊天机器人更具可扩展性且更易于管理**。