我做了一个性能优化 skill,把 AI Agent 从“可以试试懒加载”这类建议,拉进 harness、目标和 ledger 组成的循环里一轮轮跑。在一次 Workspace 优化里,strict profile 看到 Workstream 5089ms -> 2519ms、Report Center 10021ms -> 6762ms。但最重要的第一轮不是提速,而是修 FMP 测量契约。没有这一步,后面的数字都不值得信。
真正的问题
目标看起来很简单:优化 Workspace FMP。
实际目标更严格:
| 指标 | 目标 |
|---|---|
| 子应用 FMP P90 | 2.5s |
| Workspace shell FMP | 1s |
这就是普通 AI 写代码不够用的地方。如果你让 Agent “把 FMP 变快”,它会很自然地给你懒加载、拆包、预取、缓存、SDK 延迟初始化这些建议。它们有些可能正确,但没有 harness,Agent 优化的是故事,不是系统。
所以我把 skill 的核心契约设计成:
1 | No strict measurement, no performance claim. |
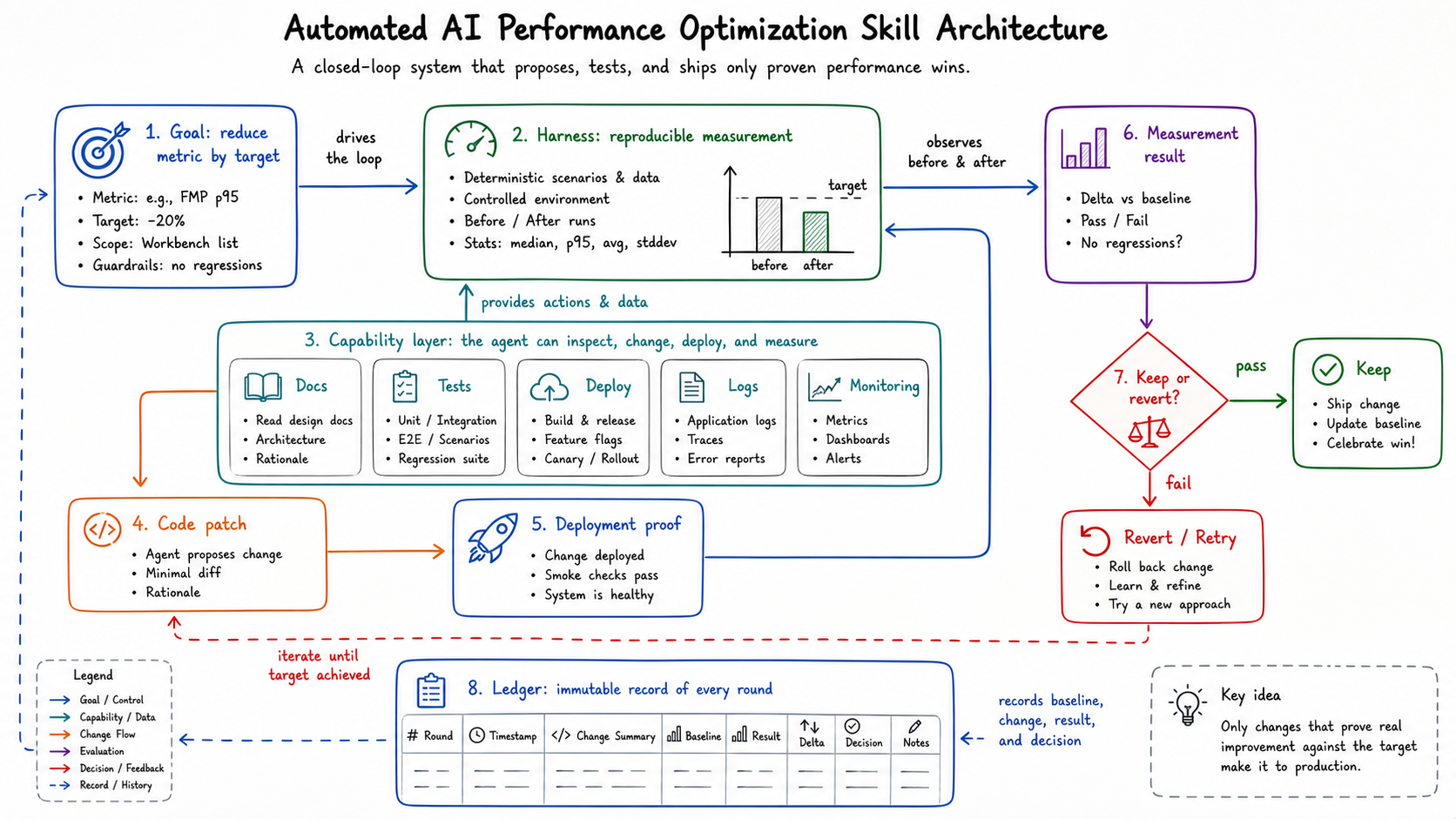
图:这个 skill 的结构:目标、harness、能力层、代码修改、部署证明和 ledger。generated by gpt-image-2.
Agent 可以写代码,但代码只是闭环中的一步。这个闭环要负责 profiling、waterfall 诊断、本地验证、部署、严格对比和文档记录。
这里还有一个容易被低估的点:性能 Skill 不是孤立脚本,它依赖更底层的 full-cycle 研发 Skill。
性能优化真正麻烦的部分通常不在“想到一个优化点”,而在后半段:本地门禁要过,patch 要提交,pipeline 要证明构建的是目标 commit,泳道要证明运行时版本正确,profile 要在同一路由、同一限速和同一登录态下重跑。如果这些步骤靠人盯着,Agent 再聪明也只是写 patch;如果这些步骤进入 Skill contract,Agent 才能持续跑 round。
换句话说,性能 loop 是一个 Ralph Loop 风格的长期迭代,但它的退出条件不是“Agent 觉得好了”,而是外部 harness 和部署证据同时通过。
先修 Harness,再谈优化
最有价值的第一条 ledger 记录很难看:生产路由没有为被测子应用发出有效 final FMP report。
几个典型症状:
| 症状 | 为什么重要 |
|---|---|
window.custom_performace 最后变成 {} |
子应用找不到 host 侧起始时间 |
一些路由发出 not_access_from_url |
子应用拒绝上报 final FMP |
一些页面只有 reactSubAppInit 这类 fallback mark |
这些只是诊断点,不是业务 FMP |
| Workstream list 没有 final list FMP event | 页面能打开,但 harness 没有权威 cutoff |
根因不是某个 chunk 慢,而是测量数据结构烂。
Host 写一种 key,子应用读另一种 key;一个 idle reset 还能把整个 map 清掉。更糟糕的是,一些子应用用 Object.keys(window.custom_performace).length === 1 来判断是否直达路由。一个 timestamp map 同时承担数据存储和状态机职责,这就是坏设计。
所以第一轮修的不是性能,而是测量:
- 保留并规范化 host FMP session。
- 写入 canonical app key,而不是 route-shaped key。
- 把 direct-route source 变成显式 session。
- 每个子应用只校验自己的 expected key。
- 补齐缺失的 final FMP reporter,尤其是 Workstream list。
这件事本身对用户可见路径是 0ms 收益,但它让后续收益可信。性能闭环必须能做这种事,而没有约束的 Agent 往往会跳过它。
Goal-Driven Loop 怎么跑
这个 skill 一轮只做一件事:
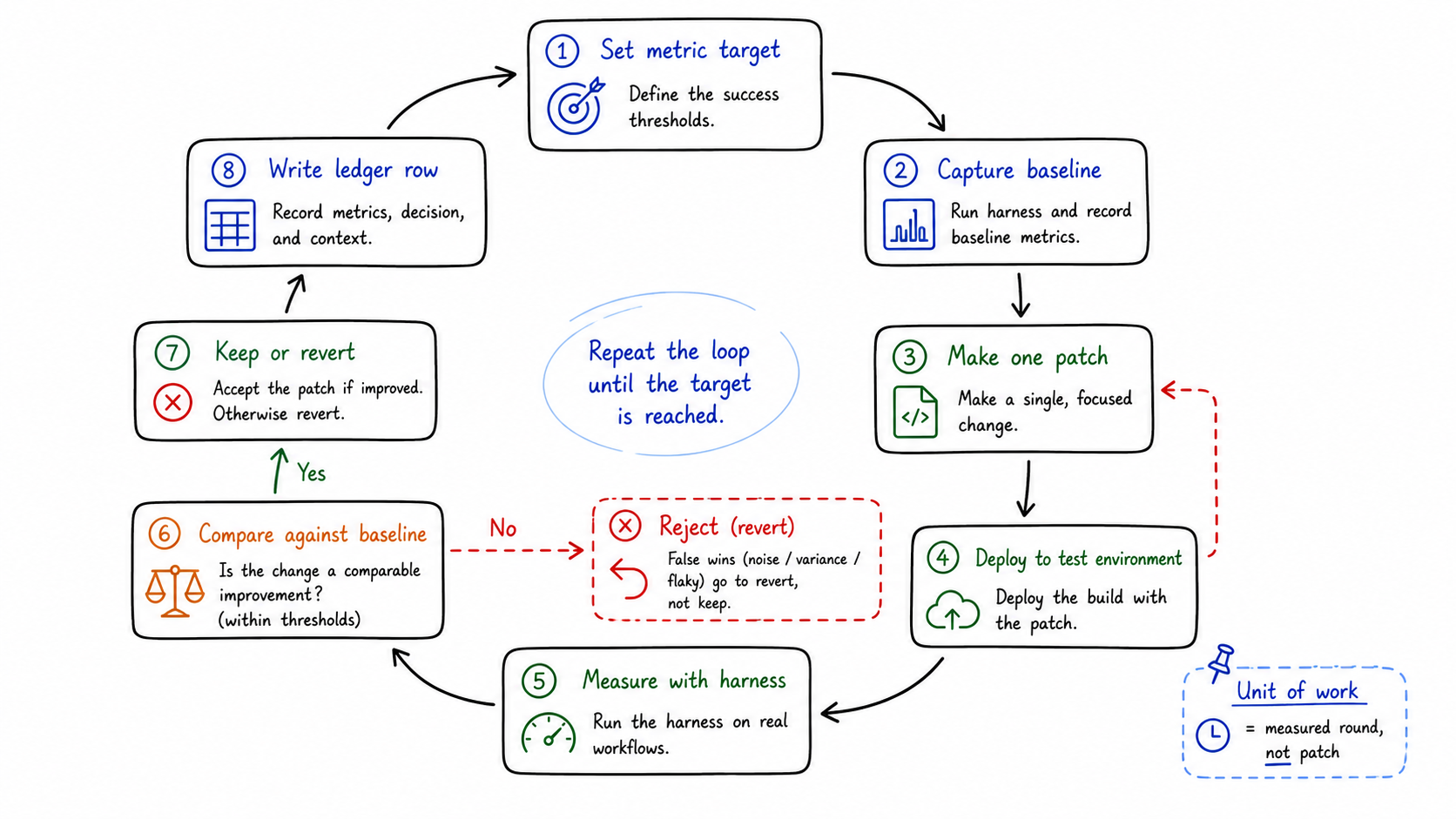
图:一个 measured round,而不是一个 patch,才是工作单元。generated by gpt-image-2.
1 | profile -> waterfall -> diagnose -> fix -> local verify -> commit/push |
每次 strict profile 都使用同一类采集条件:
- 已登录路由;
- 目标部署泳道请求头;
- 同一路由和 final marker;
- CPU 4x slower;
- fast 4G 网络;
- disabled cache;
- 与生产路径一致时启用 Service Worker;
- 运行时版本证明。
Verdict 是系统的一部分:
| Verdict | 含义 |
|---|---|
| strict win | 同一路由、同一 marker、同一限速,结果变好 |
| directional | 有参考价值,但不是严格对比 |
| measurement repair | harness 错了,不声明性能收益 |
| not a win | 指标或用户体验回退 |
| not measured | 代码发出去了,但没有有效 profiling 对比 |
这看起来像流程洁癖。等你遇到一次失败优化,就知道这是工程和自我欺骗的分界线。
如果把这个 loop 压成最小 skill contract,我只会保留这些规则:
1 | Run measured rounds until the goal is reached. |
成功落地时改了什么
测量契约修复后,loop 才开始优化真实瓶颈。
下面是 strict profile 摘要:
| App / route class | Before FMP | After FMP | Delta | Main reason |
|---|---|---|---|---|
| Workstream | 5089ms | 2519ms | -2570ms / -50.5% | 删除启动阶段无关 payload,预热 list API,把 notification/DnD/editor/actions 移到 final FMP 之后 |
| Report Center | 10021ms | 6762ms | -3259ms / -32.5% | 把 notification 移到 FMP 后,并修复 prefetch body/cache-key 对齐 |
| Scheduling | 10367ms | 7630ms | -2737ms / -26.4% | 等待真实 final marker,并在 core data ready 后立刻启动依赖 init 的预取 |
| Audit Workbench | 12610ms | 10188ms | -2422ms / -19.2% | 把 notification 移到 FMP 后,同时缩短 chunk、render 和 query timing |
另外还有一份按周追踪的 P90 视角:有些路由已经达到 2.5s 目标,有些接近目标,有些仍然没达标。这个区分很重要。严肃的性能系统应该同时记录胜利和剩余差距。
模式一:Post-FMP Scheduling 不是 Blind Deferral
最差的延迟加载方案是 setTimeout。它和产品真实可用状态没有关系。
更稳的做法是等待 route-specific final first-screen mark:
1 | function finalMarksForRoute(pathname: string): string[] { |
Notification 是一个好例子。蓝色下载条本身不一定是 parser blocker,真正的成本是 SDK/auth/callback/API/main-thread work 在 final marker 前竞争资源。把它移动到 route-specific FMP mark 之后,可以优化测量路径,同时不删除用户可见 UI。
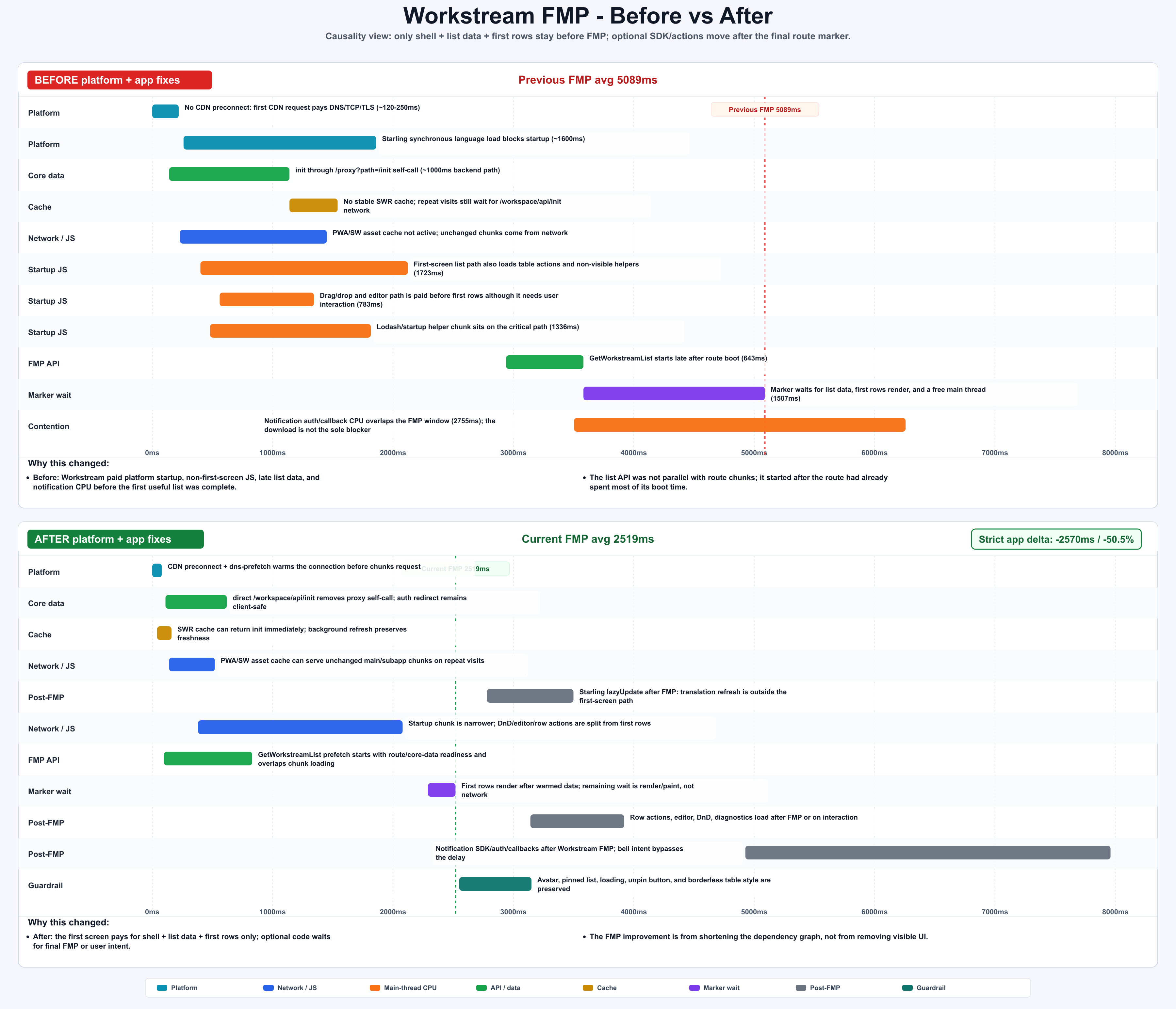
图:Workstream FMP 前后 waterfall;optional SDK/actions 被移到 final marker 之后。generated by gpt-image-2.
模式二:Prefetch 是契约,不是请求
Report Center 暴露了最糟糕的 prefetch 失败模式:host 发起了 prefetch,但 consumer 构造了不同的 body 或 cache key。网络请求确实存在,页面依然等待,于是“优化”变成了额外流量。
Ledger 最后沉淀出一句话:
1 | The cache key is the contract. |
一个有效 prefetch 必须对齐:
| 项 | 必须一致 |
|---|---|
| endpoint | 同一个 URL |
| method | 同一个 method |
| operation | 同一个 GraphQL operation 或 REST identity |
| body / variables | 同一个请求身份 |
| user context | 同一个 tenant、agent、access-party 或等价上下文 |
| consumer key | 同一个 cache key |
Consumer 仍然必须保留 fallback。如果 metadata 不匹配,就拒绝 warmed response,走正常请求。丢掉 FMP 收益可以接受,错误数据不行。
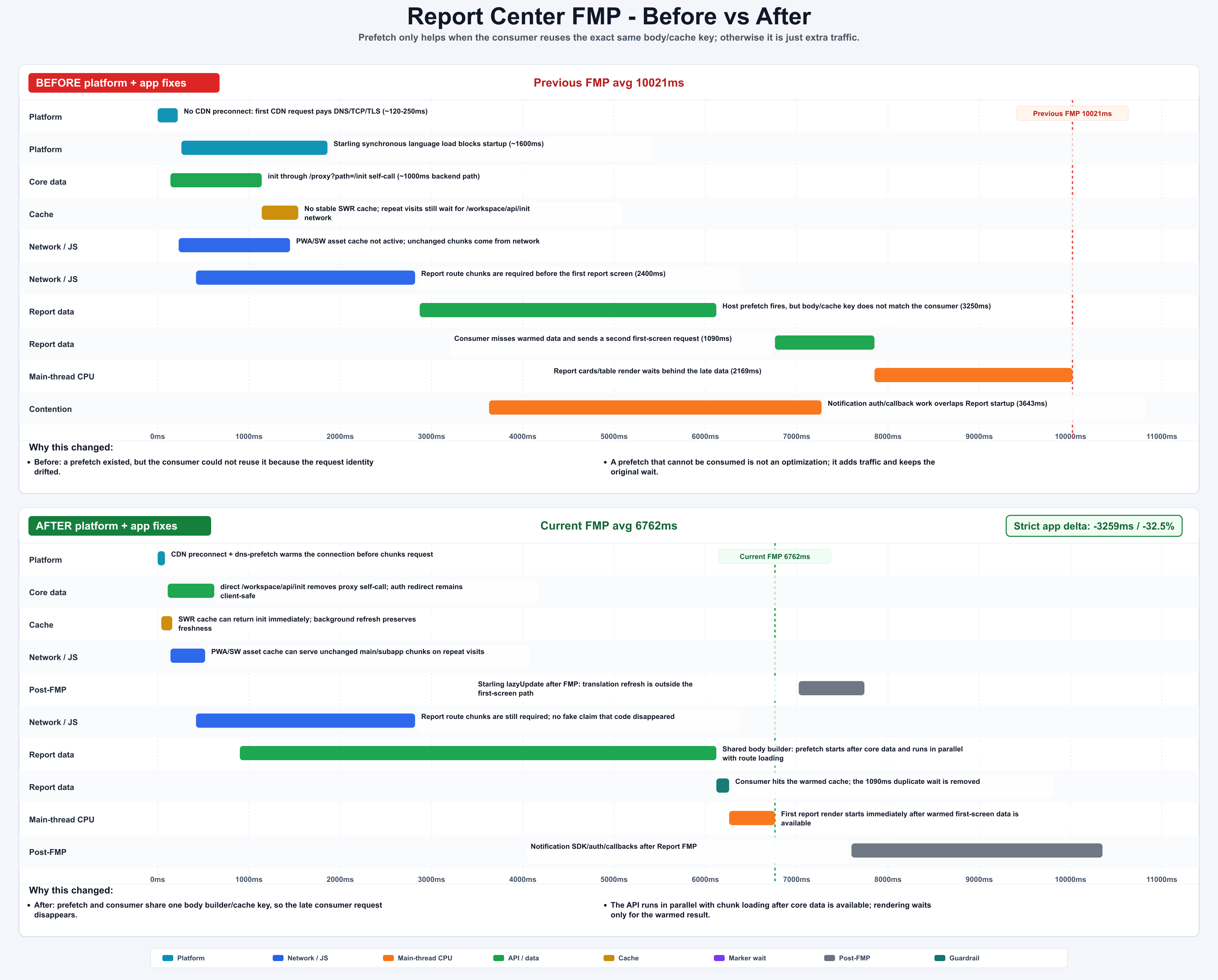
图:Report Center 修复 prefetch body/cache-key 不一致,并把 notification 移出 FMP。generated by gpt-image-2.
模式三:Cache Hit 也是 Ready Signal
系统里有两层 prefetch:
| Mode | Trigger | Suitable APIs |
|---|---|---|
| HTML inline prefetch | raw navigation time | 不依赖 user/core data 的 route-deterministic API |
| core-data-ready prefetch | /workspace/api/init 数据存在后立刻开始 |
需要 tenant、agent、access-party 上下文的首屏 API |
关键点:Service Worker 或 memory cache 命中 init data,也是有效 ready signal。如果 core data 更早可用,依赖它的 prefetch 就应该更早启动。不要把缓存数据当成二等路径。
这也是 goal-driven loop 的价值。Prefetch 有真实成本:带宽、后端压力、缓存内存、错误数据风险。Skill 只接受首屏请求确定、用户安全、并且能用完全相同 key 消费的 prefetch。
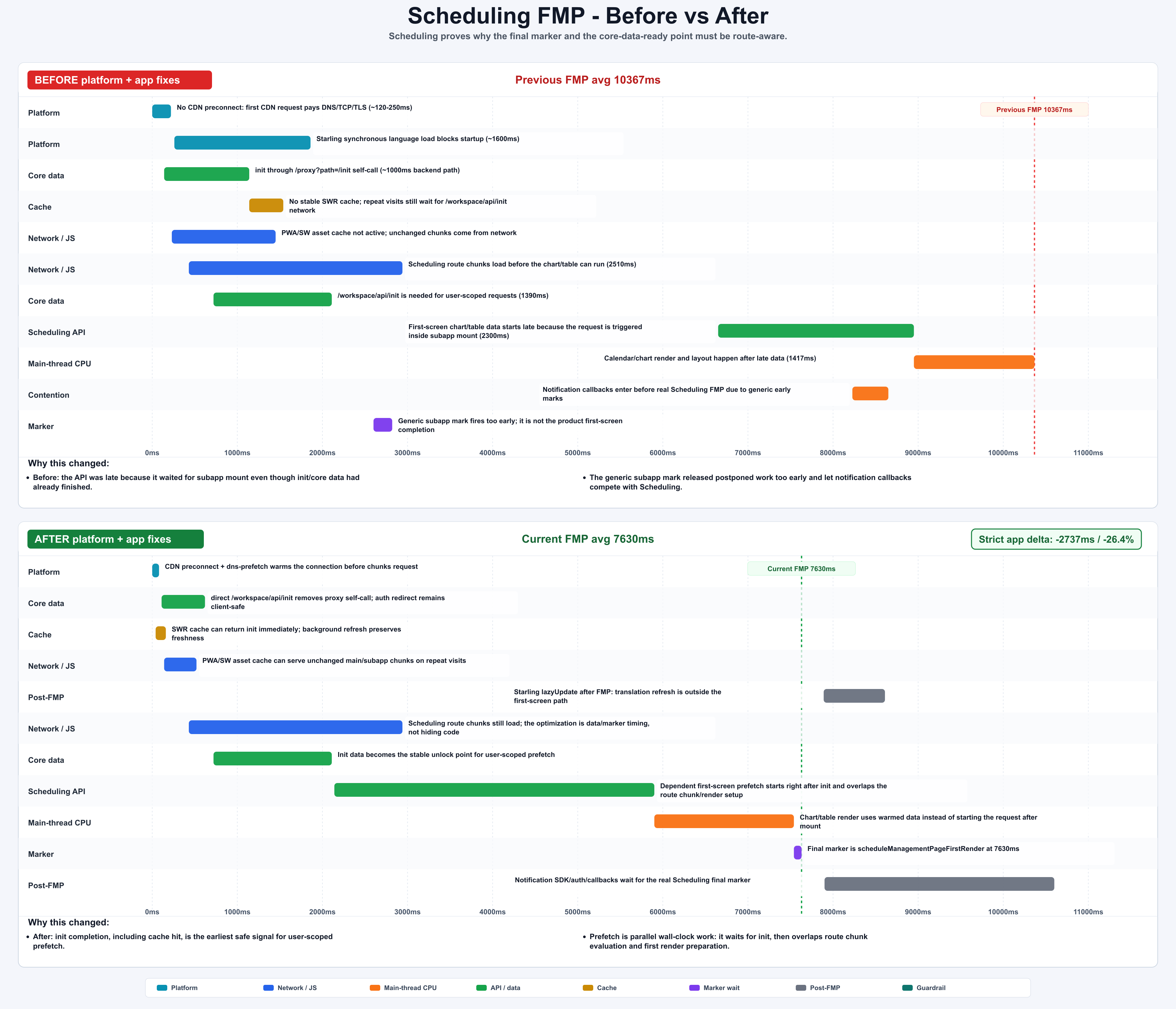
图:Scheduling 等待真实 final marker,同时更早启动依赖 core data 的 prefetch。generated by gpt-image-2.
模式四:Correctness Guard 也是性能工作
一次中间态 Workstream 优化改坏了可见细节:avatar、pinned section、loading、table border 和 unpin button 样式。Ledger 把它标为 correctness guard,而不是性能收益。
这是正确判断。一个更快但坏掉的页面,不叫优化。
最终版本保留 UI,同时把非首屏工作移出 FMP path。这听起来很显然,但它必须写进 skill。否则 Agent 很容易优化图表,破坏产品。
类似的失败 round 后来都变成了 ledger 里的 hard evidence:
| 尝试 | 看起来为什么对 | Harness 发现什么 | 结论 |
|---|---|---|---|
| 更早触发首屏预取 | 本地一次 marker 提前 | 可比 profile 显示重复请求,P90 没有稳定改善 | 回滚 |
| 延后加载重组件 | 初始 JS 成本下降 | 首次交互承接延后成本,可见后 long task 变差 | 回滚 |
| 复用 warm cache | 第二页体感更快 | 不同筛选状态下出现陈旧首屏数据 | 回滚 |
| 合并 render update | render 次数下降 | 目标指标仍在噪声区间 | 不算性能收益 |
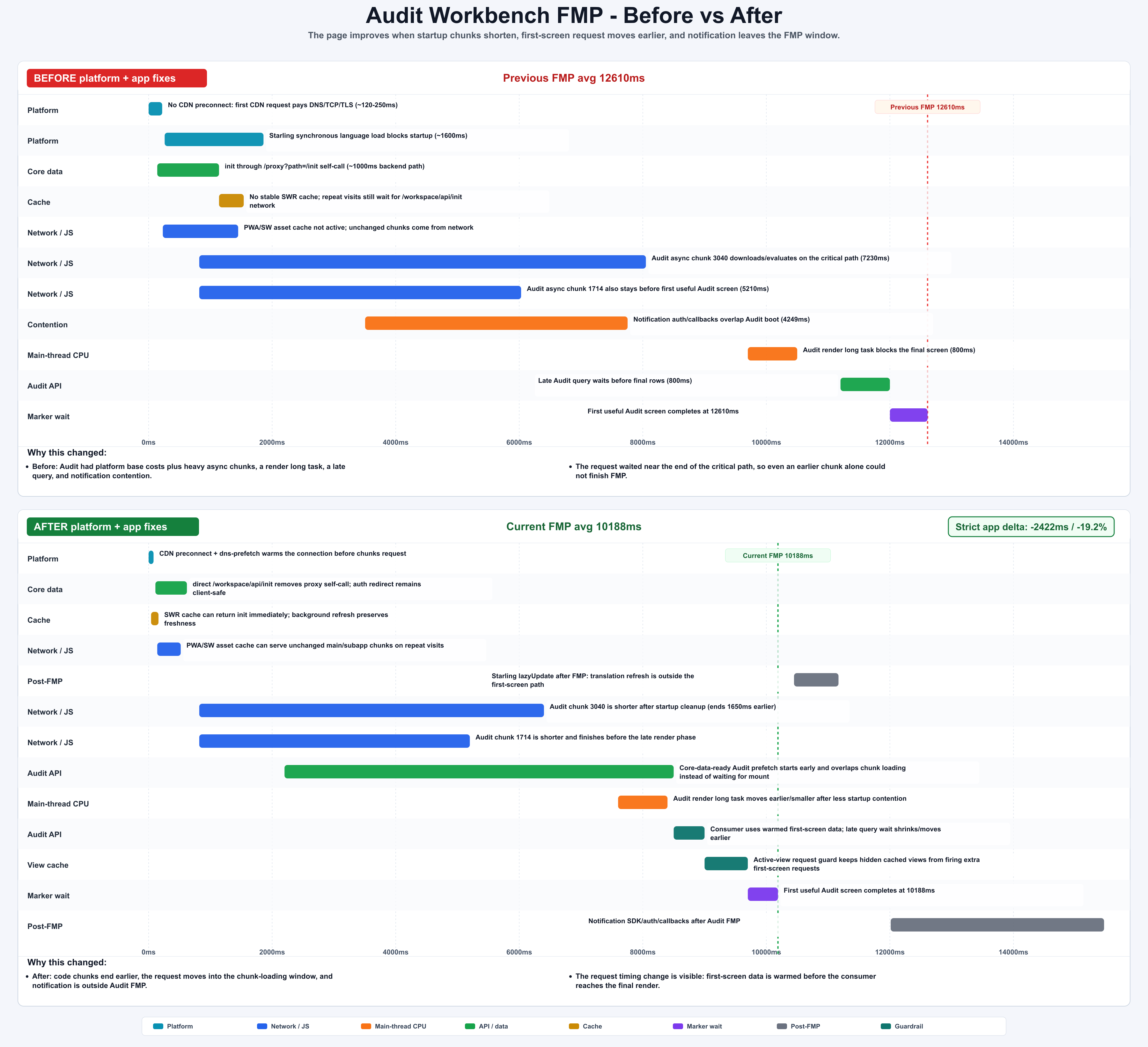
图:Audit Workbench 同时处理 chunk、render、query 和 notification;总 delta 来自 strict profile。generated by gpt-image-2.
Ledger 是控制面
Ledger 不是日记,它是这个 loop 的控制面。

图:ledger 防止假进展被接受为真进展。generated by gpt-image-2.
最有用的 ledger 规则都很硬:
| Ledger rule | 为什么重要 |
|---|---|
| 上一次有效 strict profile 是下一次 baseline | 不允许拿方便的数字对比 |
| Measurement repair 不是 performance win | 先有正确数字,再谈聪明优化 |
| 如果 capture 命中 SSO,丢掉 | 登录页 FMP 不是应用 FMP |
shell-visible 变好但 post-visible jank 变差,标 not a win |
不要把痛点挪到可见之后 |
| 一个瓶颈、一个 patch、一个 comparison | 避免叠猜测 |
这就是为什么它是 goal-driven,而不是 prompt-driven。Goal 选指标,harness 判断证据是否合法,ledger 决定这一轮能不能被接受。
我会复用什么
你不需要同样的内部基建,也可以复用这个设计。
可复用的结构是:
- 选一个用户可感知指标。
- 为它搭一个可重复 harness。
- 改代码前先定义 strict comparison 规则。
- 把上一次有效 profile 作为下一轮 baseline。
- 每轮只让 Agent 攻击一个瓶颈。
- 把 measurement repair、regression、correctness fix 都当成一等结果。
- Ledger 记录证据,不记录流水账。
技术细节会随产品变化,但这个 loop 值得保留。
我在意的结果不是 AI 某一次写出了聪明 patch,而是它能按证据跑完整工程过程:观察、选择、修改、部署、对比、记录,然后继续。