背景和目标
Tab system 引入后,工作台不再只有一个前台页面。用户可以同时打开多个 workstream、子应用和对象页,系统背后也会同时存在更多 route、runtime、iframe、SDK 和后台任务。性能问题因此不再只是单页 FMP,而是资源归属:当前 tab 要什么,后台 tab 能做什么,未来可能用到的东西什么时候才能启动。
用户只关心当前 tab 是否足够快、是否能立刻操作。但系统背后,hidden tab、预热任务、子应用 SDK、iframe runtime 和监控/埋点都可能同时活着。优化不能只盯着某条瀑布图变短,而是三条用户路径分别要守住。
图 0:一个通用工作台里的 tab system 演示。性能问题之所以变复杂,是因为多个工作对象可以同时保持打开,但只有当前 tab 应该可交互并占用前台资源。
| 路径 | 问题 | 指标与接受标准 |
|---|---|---|
| First Load / FMP | 用户第一次进入工作台或子应用时,只想看到当前页面,但网络和主线程可能在为未来路径、非当前子应用或低优 SDK 付费 | route FMP、关键资源瀑布、首屏 API。只有 blocker 前移、消失或缩短,并且最终 FMP 变好,才算收益 |
| Hot Tab Switch | 用户点了已打开的 tab,页面可能已经显示,但还不能点击,或者可见后被 long task 卡住 | tab switch v3、post-visible blocking、long task。只看 shell visible 不算完成 |
| Background Pressure | hidden tab、prewarm、SDK、WebSocket、埋点和监控任务可能在用户切换时抢前台主线程 | long task、frame gap、foreground lease、C02 stress gate。后台任务必须服从前台 tab |
业务目标和技术目标分开看:
| 目标 | 工程约束 |
|---|---|
| 用户可以同时打开多个工作流、子应用和对象页 | 首屏、热切换、后台任务不能因为多 runtime 常驻而明显变慢 |
| tab 切换接近浏览器体验 | 不能靠每次重载页面换内存,也不能靠无限保活换切换速度 |
| 刷新、分享、多窗口、子应用 SDK 行为保持不变 | 性能优化不能破坏 tab 状态恢复、业务 URL、多窗口同步和子应用打开意图 |
| 收益必须可信 | FMP、tab switch、本地 stress gate 分开度量,不把不同环境的数字混成一个总收益 |
优化原则:
先判断当前用户路径,再决定资源应该前移、延后、保活还是取消。每个性能收益都要能在瀑布或 timing 图里看到 blocker 的移动、消失或缩短。
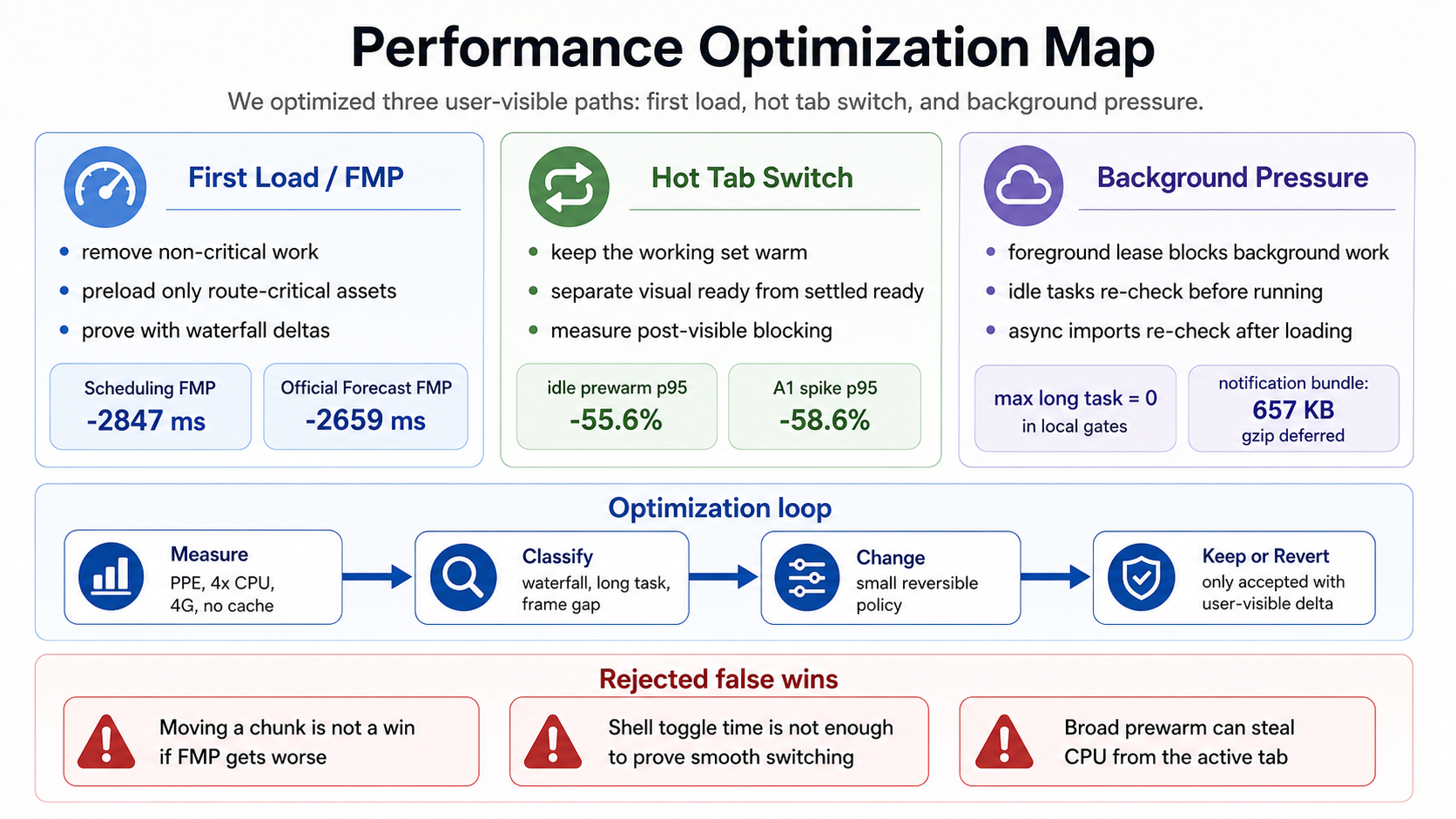
图 P1:Performance optimization map。它把优化分成首屏关键路径、热切换、后台压力三类,也列出几个被拒绝的伪收益。
项目规模和结果口径
线上周报口径里,目标是:Workspace shell P90 接近 1s,子应用 on Workspace P90 接近 2.5s。早期基线里,所有主要模块都没达标,Scheduling 和 Report Center 这类路径尤其明显。
下面这张表只用于说明项目规模和趋势。它是周报 P90 口径,不等同于后文每个 round 的 strict preview profile。
| Module | Early weekly FMP | Later weekly FMP | Target | Trend |
|---|---|---|---|---|
| Workspace shell | 2049ms |
1718ms |
1000ms |
-16.2% |
| Report Center | 6996.95ms |
2741ms |
2500ms |
-60.8% |
| Scheduling | 8313ms |
2342ms |
2500ms |
-71.8% |
| Omni Workbench | 3186.9ms |
2485ms |
2500ms |
-22.0% |
| Field Management | 4054.56ms |
3613ms |
2500ms |
-10.9% |
这个表的意义不是“所有问题都解决了”。恰恰相反,它说明这件事不是靠一个技巧收尾:有些模块已经接近或达到目标,有些还需要继续拆瓶颈。后文的 strict profile 只对具体改动负责,不拿周报趋势冒充单轮收益。
所以后面的结构不按 commit 写,而按工程问题写:问题规模是什么,指标怎么定义,资源归属怎么设计,哪些方案被拒绝,以及每个收益如何被 strict profile、stress gate 或 E2E correctness gate 证明。
结论和收益
| Area | 问题 | Before | After | Delta | Evidence |
|---|---|---|---|---|---|
| Scheduling | route chunks 发现太晚,覆盖最终 FMP 窗口 | route FMP 14773ms |
11926ms |
-2847ms / -19.3% |
strict preview waterfall;route chunks 从晚发现改成 route-aware preload |
| Official Forecast | route-critical CSS 到最后才被发现 | route FMP 14271ms |
11612ms |
-2659ms / -18.6% |
strict preview waterfall;CSS 从约 13.8s 提前到约 1.9s |
| Workspace FMP cleanup | host uploader 在所有主路径首屏前启动 | pre-FMP count 7/7 routes |
0/7 routes |
主跑 6/7 路径改善,平均约 -1037ms |
strict FMP loop;作为 cleanup pattern 说明 |
| Seto entry fanout | 非当前 Seto entry 抢当前 route 的首屏资源 | affected routes 5 |
0 |
平均约 -366ms vs previous accepted run |
strict FMP loop;非当前 Seto entry 后移 |
| Cold tab switch | 用户点击后才加载 runtime 和恢复视图 | p95 duration 1829.8ms |
812.3ms |
-55.6% |
strict tab-switch probe;idle prewarm |
| Cold tab switch | frame 已经 visible,但用户仍被阻塞 | p95 post-visible blocking 1193.7ms |
8.7ms |
-99.3% |
strict tab-switch probe;blocking 从点击后移到点击前 |
| Spike control | hidden prewarm 和后台 SDK 抢前台主线程 | A1 p95 duration 1700.1ms |
703.1ms |
-58.6% |
strict tab-switch probe;切换中暂停 hidden prewarm |
| Background pressure | 后台 SDK 未来可能制造新的切换卡顿 | max long task present risk | max post-visible long task = 0 | guardrail, not preview-environment main win | local C02 stress gate;Notification/WebSocket/Tea/Slardar 进入 scheduler |
注意两点:
- 严格 preview FMP、strict tab-switch、本地 C02 gate 不混在一起算总收益。
- “移动了资源”不自动等于收益。只有用户指标变好,并且图里能解释原因,才算保留。
测量口径
FMP 严格对比使用同一套环境:
- authenticated preview environment;
- target preview-lane headers;
- browser cache disabled;
- CPU 4x throttle;
- 4G network throttle;
- 同一批 route 和同一类最终 FMP marker;
- 失败实验保留记录,不把回滚项算收益。
Tab switch 使用 v3 指标,不再只看“点击后 frame 显示用了多久”:
| v3 字段 | 含义 |
|---|---|
inputDelayMs |
用户输入到 React handler 开始,捕捉主线程排队 |
shellVisibleMs |
handler 到 focused hot frame 可见 |
interactiveReadyMs |
目标 tab 可以响应 |
postVisibleBlockingMs |
frame 已经可见但用户仍被阻塞的时间 |
postVisibleJankMs |
可见后的 frame gap / long task |
settledReadyMs |
到 500ms quiet window,兼容旧 duration 但语义更明确 |
这次优化里最重要的测量修正是:旧指标可能显示几十毫秒,但 strict probe 会看到可见后还有上百到上千毫秒 long task。后续只接受能降低 post-visible blocking 或最终 FMP 的优化。
测量和门禁
收益不是来自一次手测。我们把验证拆成三套 harness,每套只回答一个问题。
| Harness | 怎么跑 | 采集什么 | 接受或拒绝什么 |
|---|---|---|---|
| Strict preview FMP profiler | 登录态 CDP Chrome;target preview route;target preview-lane headers;禁用缓存;CPU 4x;4G;每次从 clean root-tab 开始;30s capture | route FMP、subapp load-start、关键资源瀑布、pre-FMP resource count | 只有同一路由、同一 marker 的 previous/current delta 变好,并且瀑布能解释 blocker 前移、消失或缩短,才算 FMP 收益;资源变“干净”但 FMP 变差就拒绝 |
| Strict tab-switch probe | CDP 驱动真实 tab 激活;样本覆盖 Workstream native、Workstream 内 Seto/Supervisor、其它已打开 tab;v3 从真实 input timestamp 开始,等到 visible 后稳定帧/quiet window | inputDelayMs、shellVisibleMs、interactiveReadyMs、postVisibleBlockingMs、postVisibleJankMs、frame gap、long task |
只看 frame visible 不算热切换收益。p95/max、可见后阻塞和 worst sample 都改善,才接受;单次漂亮样本不够,需要重复 strict profile |
| Local stress gate | workspace tab-switch stress spec;mocked backend + 真实浏览器;20 个打开 tab、5 个 hot workstream cache、overlay containment、后台 SDK/预热任务同时存在 | hot switch summary、post-visible blocking、long task、warm-pool count、cache miss、overlay hit-test | 这是防回归 gate,不当作 preview 主收益。它要求没有新的 post-visible long task,warm-pool 上限仍成立,hidden tab 和 overlay 不抢前台交互 |
E2E 用例保护的是“优化没有破坏 tab system 的正确性”。mock-off 集成用例通过 preview-lane routing 连接真实后端,不把 mock 数据误当成 preview 结果。
| 用例 | 验证的问题 | 它防住的性能回归 |
|---|---|---|
| Cold/hot switch | 从 workstream 发起 cold/hot switch,记录 readiness、post-visible blocking、long task | idle prewarm 或 warm-pool 改动不能把加载挪到用户看见之后 |
| Stress switch | 20-tab / 5-hot-workstream stress switching,同时检查 overlay containment | 大工作集下热切换不能靠无限保活取巧;后台 tab、cache eviction、overlay 都不能影响前台 |
| Preview routing | mock-off 生效,preview routing 到达 workspace backend | 如果环境不对,所有 FMP / tab-switch 数字都不进入结论 |
| Tab backend contract | tab/list/add/remove/pin/unpin/reorder 和异常 payload |
React Query / optimistic mutation 优化不能制造脏 tab list、重复 tab 或错误顺序 |
| Refresh recovery | 刷新后仍恢复业务 URL;per-tab session state 形状正确 | per-tab URL persistence 和 cache 改动不能破坏刷新、分享、恢复 |
T-BCH-C01, C03 |
A 窗口新增或关闭 tab 后,B 窗口通过 BroadcastChannel 同步 | 多窗口不能只靠当前窗口 React state;否则性能优化后会出现一个窗口快、另一个窗口脏 |
| Subapp open intents | 子应用 open request、legacy navigation、去重、非法 payload、origin reject、bus-v2 行为 | SDK bridge 延迟、合并或重构后,子应用打开 tab 的意图不能丢、不能重复、不能越权 |
T-LFC-C01 |
focus 切换时发出 TAB_BLURRED 再发 TAB_FOCUSED |
后台 tab 必须真的进入后台;否则 polling、WebSocket、prewarm 会继续抢主线程 |
优化地图
这张表不是 commit 清单,而是后面章节的索引。每一行都按同一个顺序写:先写问题,再写 blocker 或原因,再写方案,最后写证据和防误判。
| 类别 | 问题 | blocker / 原因 | 方案 | 证据 / 收益 | 防误判 |
|---|---|---|---|---|---|
| Measurement contract | 旧 tab switch duration 看起来很快,但用户仍可能看见后点不动;FMP 实验如果只看资源数量,也会把伪收益当收益 | shell visible 和 interactive 混在一起;本地 gate、preview FMP、strict switch 口径不同 | FMP 看最终首屏 marker;tab switch v3 看 input、visible、interactive、post-visible blocking;C02 只做防回归 | 后续优化都能定位到 blocker 前移/消失/缩短,或 post-visible blocking 降低 | measurement repair 本身不算性能收益 |
| Critical-path reduction | 当前页面还没首屏,网络和主线程却在服务未来路径 | Workstream list、host uploader、AIS、非当前 Seto entry fanout 进入 pre-FMP | 当前 route 首屏前只保留必要工作;其它 SDK 和非当前 runtime 到 first-screen ready 后再调度 | /workspace/api/workstream/list 在 6/7 root-subapp 路径从 pre-FMP 移出;host uploader 7/7 -> 0/7;Seto fanout affected routes 5 -> 0 |
只延后不属于当前首屏的工作;资源移走但 FMP 变差就回滚 |
| Route-critical early start | 真正挡首屏的 route 资源太晚被发现 | Scheduling chunks 在 6785ms-15464ms 才出现;Official Forecast CSS 到 13789ms-14988ms 才出现 |
对 route-critical 资源做定向提前发现:Scheduling route chunks、Official Forecast CSS | Scheduling FMP 14773ms -> 11926ms;Official Forecast FMP 14271ms -> 11612ms |
不是 preload 越多越好,只提前证明挡首屏的资源 |
| Runtime cache | 用户切回 tab 后希望马上可操作,但不能无限保活所有 runtime | 冷切换时点击后才加载 runtime、恢复视图、等待 iframe/subapp ready | opened tabs、hot runtime、view cache 分层;WarmPool 保最近工作集;IdlePrewarm 在首屏后准备可能切回的 runtime | cold switch p95 1829.8ms -> 812.3ms;post-visible blocking 1193.7ms -> 8.7ms |
hot 不是 opened;Seto sandbox 更重,预热要更谨慎 |
| Main-thread scheduling | 用户切换时,hidden prewarm 或 SDK 初始化抢前台主线程 | async import 检查时安全,bundle 下载完后前台可能已经在切换 | foreground-aware scheduler;import 前、import 后、init 前、render/open 前都 re-check | A1 p95 1700.1ms -> 703.1ms;C02 gate max post-visible long task = 0 |
Notification/WebSocket/Tea/Slardar 作为 guardrail,不夸成 preview FMP 主收益 |
| Reject false wins | 瀑布更干净或 frame 更快 visible,不代表用户更快 | 资源数量、shell visible、局部 memo 都可能制造漂亮但错误的数字 | 把资源移动当 hypothesis;strict profile 变差就回滚 | Swimlane chunk 平均 FMP +1217ms 回滚;all-hot strict p95 到 1792.0ms 且有 517ms post-visible long task |
用户指标优先,causality 其次,资源形态只作为解释 |
第一类:First Load / FMP
1. 清掉不属于当前首屏的工作
问题是:用户等待当前 route 首屏时,网络和主线程却在为其它 future path 或低优 SDK 付费。方案不是固定 sleep,而是用 route-specific first-screen ready 判断哪些工作可以移到首屏后。
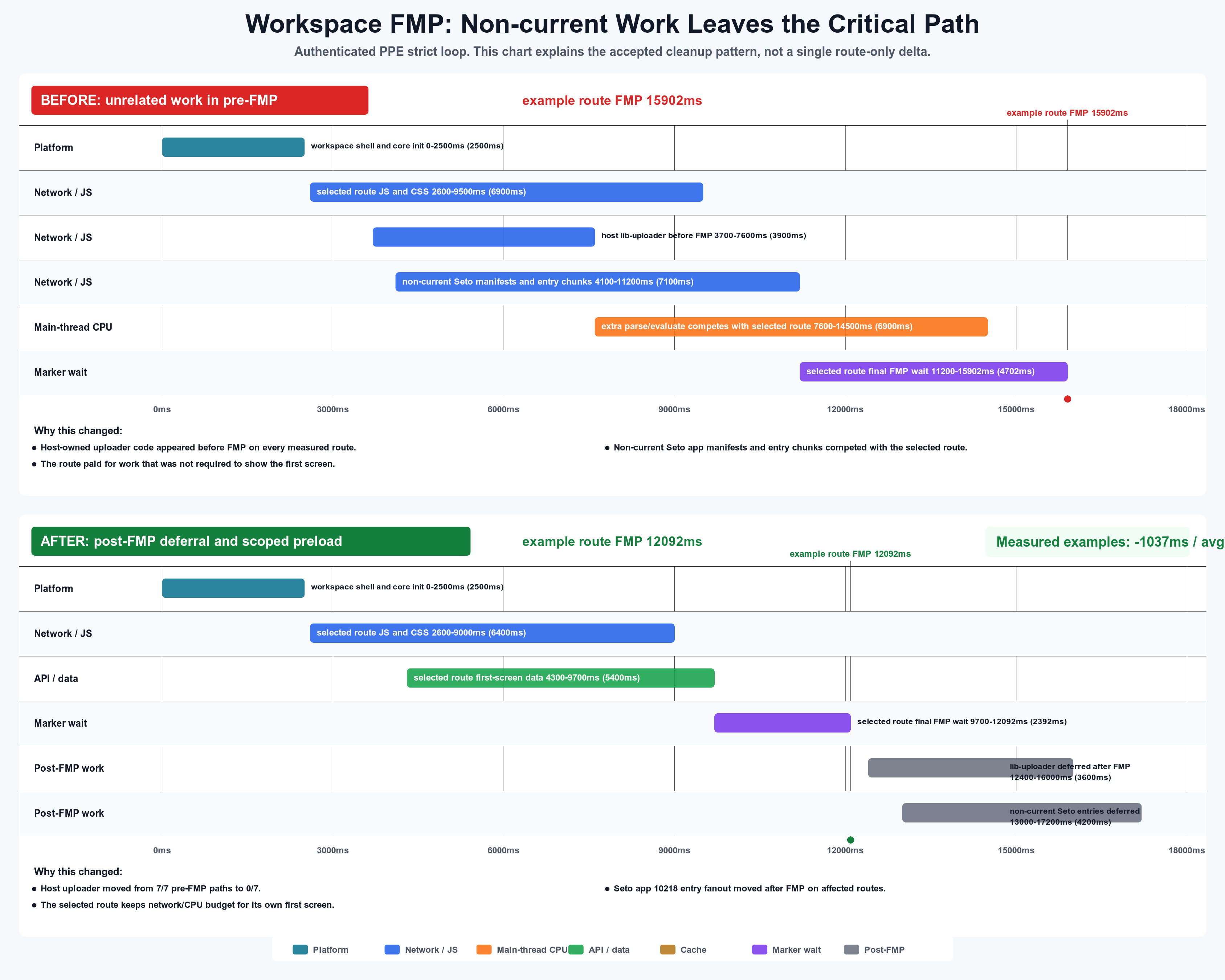
图 P2:Critical-path cleanup waterfall。它是基于严格 FMP loop 的模式图,用来解释 cleanup pattern:host uploader 从 7/7 pre-FMP 路径移到 0/7,非当前 Seto entry fanout 在受影响路径从 5 移到 0。图里的 example route 不是单一路由精确 trace,精确 route delta 见后面的 Scheduling 和 Official Forecast。
| 改动 | 首屏前的 blocker | 变化 | 收益口径 |
|---|---|---|---|
移除 pre-FMP /workspace/api/workstream/list 刷新 |
root-subapp 首屏不需要 Workstream list,却在进入瀑布 | 6/7 root-subapp 路径 pre-FMP count 降到 0 | 主跑 4/7 路径改善,平均约 -1051ms |
| 延后 AIS / uploader | host-owned lib-uploader 在 7/7 路径 pre-FMP |
7/7 -> 0/7 |
7 条主路径中 6 条改善,平均约 -1037ms |
| 延后非当前 Seto entry fanout | app 10218 manifest 和 static/js/entry.* 抢当前 route |
affected routes 5 -> 0 |
平均约 -366ms vs previous accepted run |
实现思路:
1 | // 挂载在 route first-screen ready 之后。 |
关键点是:延后的是“不属于当前首屏”的工作,不是盲目把所有资源都推后。
2. Scheduling:route chunks 从晚发现变成提前发现
问题是:Scheduling route chunks 到 6785ms-15464ms 才被 sandbox 发现,覆盖最终 FMP 窗口。原因不是网络一定慢,而是浏览器太晚知道这些 chunks 是当前首屏需要的资源。
Scheduling FMP 从 14773ms 到 11926ms,降低 2847ms / 19.3%。

图 P3:Scheduling route chunks waterfall。Before 里 route chunks 在 6785ms-15464ms 才被发现并覆盖 FMP 窗口;After 里对应 chunks 作为 link resource 在 1928ms-1961ms 启动。
代码策略:
1 | // 挂载在 route resolver 识别到 Scheduling 路由后。 |
为什么有效:
- route chunks 和首屏 data 不是必须串行;
- 提前启动 route chunks 后,它可以和 shell/data 并行;
- FMP 剩余时间主要是 Seto runtime、数据和渲染,不再是“浏览器晚发现代码”。
3. Official Forecast:CSS 是 route-critical,不能等到最后
问题是:Official Forecast 的 CSS 在 13789ms-14988ms 这个非常晚的窗口才出现,最终 marker 会等 late stylesheet discovery。方案是只提前首屏必需的 CSS,而不是盲目提前所有 route JS。
Official Forecast FMP 从 14271ms 到 11612ms,降低 2659ms / 18.6%。

图 P4:Official Forecast CSS waterfall。Before 里 CSS 在 13789ms-14988ms 这个非常晚的窗口才出现;After 里 CSS 在 1872ms-2632ms 提前启动,和 route code/data 并行。
代码策略:
1 | // 只在 Official Forecast route 命中时提前样式。 |
为什么有效:
- 这不是普通“多 preload 一个资源”;
- 这个 CSS 直接影响首屏最终渲染稳定;
- 它从 FMP 前最后一段等待中移走后,最终 marker 不再等 late stylesheet discovery。
4. 反例:Swimlane chunk 不是收益
有一次我们把 Swimlane chunk 从 pre-FMP 移走,表面上看 waterfall 更干净:pre-FMP count 7/7 -> 0/7。但严格跑下来平均 FMP 反而 +1217ms,load-start 也更差,所以回滚。
这个反例要放在正文里,因为它说明一件事:性能优化不是整理瀑布图。资源少了但用户更慢,就是失败。
第二类:Hot Tab Switch
热切换的问题不是“frame 有没有显示”,而是“用户看到后能不能操作”。所以 v3 要看 post-visible blocking。
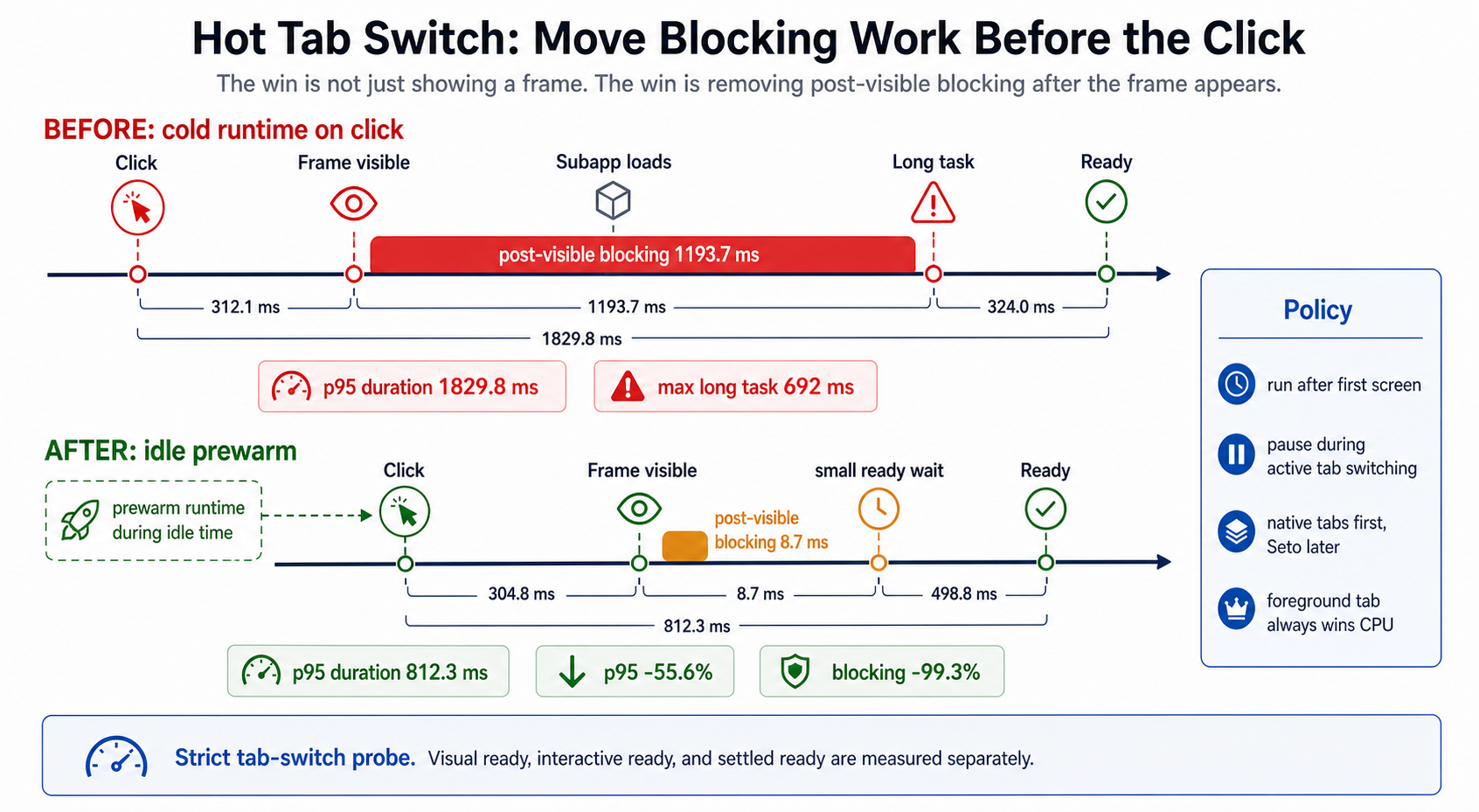
图 P5:Hot tab switch causality。Before 中,冷 runtime 在点击后加载,frame 已经 visible 之后仍有 1193.7ms blocking;After 中,idle prewarm 把主要准备工作移到点击前,post-visible blocking 降到 8.7ms。
1. Idle prewarm
问题是:冷切换时,用户点击后才开始加载 runtime、恢复视图、等待 iframe/subapp ready。frame 即使先显示出来,后面仍可能被 long task 卡住。方案是首屏完成后,在 idle 窗口准备最近可能切回的 runtime。
| 指标 | Before | After | Delta |
|---|---|---|---|
| cold switch p95 duration | 1829.8ms |
812.3ms |
-55.6% |
| visibleToReady p95 | 1693.7ms |
508.7ms |
-70.0% |
| postVisibleBlocking p95 | 1193.7ms |
8.7ms |
-99.3% |
| max post-visible long task | 692ms |
73ms |
显著降低 |
实现策略:
1 | // 挂载在首屏 ready 之后。 |
为什么有效:
- 目标 runtime 的部分加载、初始化、生命周期 prime 在用户点击前完成;
- 用户点击后不再把大量 subapp loading 和 long task 放到可见之后;
- prewarm 只跑在首屏后,不能抢首屏。
2. Runtime-aware prewarm
这里的取舍是:所有 runtime 立刻预热最简单,但 Seto sandbox 更重,容易把后台优化变成前台压力。最终策略是 native 更早,Seto 更谨慎。
| 场景 | p95 duration | visibleToReady | postVisibleBlocking |
|---|---|---|---|
| immediate cold baseline | 1853.8ms |
1657.7ms |
1157.7ms |
| runtime-aware early switch | 1285.3ms |
1029.8ms |
529.8ms |
| delta | -30.7% |
-37.9% |
-54.2% |
这说明 warm pool 和 idle prewarm 不能只看“是否提前加载”,还要看 runtime 类型、当前前台压力、切换是否正在 settling。
3. 暂停 hidden prewarm,消掉前台 spike
问题是:用户切到 Supervisor 时,hidden/background Audit Workbench、xlsx、Slardar 等任务同时抢主线程。方案是给前台 tab 一个 lease:只要前台正在切换或还没稳定,后台任务必须让路。
1 | // 所有 hidden prewarm 和后台 SDK 任务执行前都要检查。 |
收益:
| 指标 | Spike before | After | Delta |
|---|---|---|---|
| p95 duration | 1700.1ms |
703.1ms |
-58.6% |
| shell visible | 1199ms |
194ms |
-83.8% |
| interactive | 1250ms |
194ms |
-84.5% |
这说明后台优化必须有前台优先级。预热如果抢了当前 tab,就是负优化。
第三类:Background Pressure
问题是:hidden tab 仍然可能活着,Notification、WebSocket、Tea、Slardar、visit、storage health、AIS 这些任务如果按普通单页应用的方式启动,会在用户切换时制造新的 long task。方案是统一进入 foreground-aware scheduler。
1 | // 后台任务不能直接执行,必须先进入统一仲裁。 |
异步任务还要在 import / loader 前后重查:
1 | async function safeLoadSdk() { |
| 后台任务 | 改动 | 证据口径 |
|---|---|---|
| MF preload | getEntries 前后都 re-check foreground 状态 |
本地 C02:p95 visual 约 31.2ms,postVisibleBlocking 约 7.8ms,max long task = 0 |
| Notification SDK | lib-kefu-notify 约 657.2KB gzip,import/open/render 前后都 re-check |
本地 C02:postVisibleBlocking 约 7.1ms,max long task = 0 |
| WebSocket | import、init、register 前后进入 scheduler | 本地 C02:visual 42.1ms -> 36.6ms,约 -13.1% |
| Tea | flush queue 分批、让出前台 | 本地 C02:visual 31.5ms -> 29.5ms,约 -6.3% |
| Slardar / visit / storage health / AIS | 首屏后、idle、foreground-aware | guardrail;不宣称 preview 主收益 |
这些改动的价值是防止未来某个 SDK 变成新的 tab-switch 卡顿源。它们是系统稳定性的底座,不应该被夸成 FMP 主收益。
被拒绝的优化
| 实验 | 看起来合理的原因 | 为什么拒绝 |
|---|---|---|
| Swimlane chunk 移出 pre-FMP | 瀑布更干净,pre-FMP count 下降 | 平均 FMP +1217ms,用户指标变差,回滚 |
| 全量 optimistic focus / all-hot 激活 | 理论上 frame 更快 visible | strict p95 到 1792.0ms,出现 517ms post-visible long task,回滚 |
| 广泛 Seto prewarm / hidden layout-visible | 希望提前完成 sandbox 工作 | 容易抢前台 CPU,收益不稳定,未作为主方案 |
| 小组件 memo / 局部缓存实验 | 看起来能减少 render | 本地 p95 变差或没有严格收益,不保留 |
| 只看旧 tab switch duration | 数字能到几十毫秒 | 漏掉 input queue 和 post-visible blocking,指标本身不可信 |
可复用方法
- 先分路径。 FMP、tab switch、background pressure 是三类问题,不能用同一把尺子。
- 再定资源归属。 当前首屏需要的资源前移;不属于当前首屏的资源延后;未来可能需要的资源只能 idle prewarm。
- 画因果图再写结论。 图里必须能看到 blocker 前移、消失、缩短或移到 FMP 后。
- 接受失败。 资源移动但 FMP 变差,就回滚。
- 本地 gate 和 preview 收益分开写。 本地 C02 是防回归,不是线上收益。
最后真正起作用的不是某个单点技巧,而是三条比较朴素的规则:
- 首屏关键路径只保留当前 route 必要工作;
- 热切换有 bounded runtime cache 和 idle prewarm;
- 后台任务必须服从 foreground scheduler。
这比某个 patch 更重要。Workspace 只会接入更多子应用、SDK 和 runtime。没有路径分类和资源仲裁,tab 越多,性能越不可预测。